выбор индексов с многолетними наблюдениями
Я хочу выбрать только те строки, которые имеют наблюдения в течение нескольких лет. Например, предположим
mlIndx = pd.MultiIndex.from_tuples([('x', 0,),('x',1),('z', 0), ('y', 1),('t', 0),('t', 1)])
df = pd.DataFrame(np.random.randint(0,100,(6,2)), columns = ['a','b'], index=mlIndx)
In [18]: df
Out[18]:
a b
x 0 6 1
1 63 88
z 0 69 54
y 1 27 27
t 0 98 12
1 69 31
Мой желаемый результат -
Out[19]:
a b
x 0 6 1
1 63 88
t 0 98 12
1 69 31
Мое текущее решение является тупым, поэтому что-то, что может масштабироваться легче, было бы здорово. Вы можете использовать сортированный индекс.
df.reset_index(level=0, inplace=True)
df[df.level_0.duplicated() | df.level_0.duplicated(keep='last')]
Out[30]:
level_0 a b
0 x 6 1
1 x 63 88
0 t 98 12
1 t 69 31
4 ответа:
Вы можете вычислить это с помощью
groupby(на первом уровне индекса) +transform, а затем использовать логическое индексирование для фильтрации этих строк:df[df.groupby(level=0).a.transform('size').gt(1)] a b x 0 67 83 1 2 34 t 0 18 87 1 63 20подробности
Выходные данныеgroupby-df.groupby(level=0).a.transform('size') x 0 2 1 2 z 0 1 y 1 1 t 0 2 1 2 Name: a, dtype: int64Фильтрация отсюда проста, просто найдите те строки с размером > 1.
Используйте группу по
filter
Вы можете передать функцию, которая возвращает логическое значение вdf.groupby(level=0).filter(lambda x: len(x) > 1) a b x 0 7 33 1 31 43 t 0 71 18 1 68 72
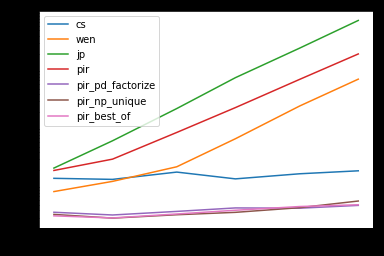
Я потратил свою долю времени на то, чтобы сосредоточиться на скорости. Не все решения должны быть самыми быстрыми. Впрочем, раз уж эта тема поднялась. Я предложу то, что, по моему мнению, должно быть быстрым решением. Я намерен держать будущих читателей в курсе событий.Результаты теста времени
res.plot(loglog=True)
res.div(res.min(1), 0).T 10 30 100 300 1000 3000 cs 4.425970 4.643234 5.422120 3.768960 3.912819 3.937120 wen 2.617455 4.288538 6.694974 18.489803 57.416648 148.860403 jp 6.644870 21.444406 67.315362 208.024627 569.421257 1525.943062 pir 6.043569 10.358355 26.099766 63.531397 165.032540 404.254033 pir_pd_factorize 1.153351 1.132094 1.141539 1.191434 1.000000 1.000000 pir_np_unique 1.058743 1.000000 1.000000 1.000000 1.021489 1.188738 pir_best_of 1.000000 1.006871 1.030610 1.086425 1.068483 1.025837Детали Моделирования
def pir_pd_factorize(df): f, u = pd.factorize(df.index.get_level_values(0)) m = np.bincount(f)[f] > 1 return df[m] def pir_np_unique(df): u, f = np.unique(df.index.get_level_values(0), return_inverse=True) m = np.bincount(f)[f] > 1 return df[m] def pir_best_of(df): if len(df) > 1000: return pir_pd_factorize(df) else: return pir_np_unique(df) def cs(df): return df[df.groupby(level=0).a.transform('size').gt(1)] def pir(df): return df.groupby(level=0).filter(lambda x: len(x) > 1) def wen(df): s=df.a.count(level=0) return df.loc[s[s>1].index.tolist()] def jp(df): return df.loc[[i for i in df.index.get_level_values(0).unique() if len(df.loc[i]) > 1]] res = pd.DataFrame( index=[10, 30, 100, 300, 1000, 3000], columns='cs wen jp pir pir_pd_factorize pir_np_unique pir_best_of'.split(), dtype=float ) np.random.seed([3, 1415]) for i in res.index: d = pd.DataFrame( dict(a=range(i)), pd.MultiIndex.from_arrays([ np.random.randint(i // 4 * 3, size=i), range(i) ]) ) for j in res.columns: stmt = f'{j}(d)' setp = f'from __main__ import d, {j}' res.at[i, j] = timeit(stmt, setp, number=100)
Просто новый способ
s=df.a.count(level=0) df.loc[s[s>1].index.tolist()] Out[12]: a b x 0 1 31 1 70 29 t 0 42 26 1 96 29И если вы хотите продолжать использовать дубликат
s=df.index.get_level_values(level=0) df.loc[s[s.duplicated()].tolist()] Out[18]: a b x 0 1 31 1 70 29 t 0 42 26 1 96 29
Я не уверен, что
groupbyнеобходимо:df = df.sort_index() df.loc[[i for i in df.index.get_level_values(0).unique() if len(df.loc[i]) > 1]] # a b # x 0 16 3 # 1 97 36 # t 0 9 18 # 1 37 30Некоторые бенчмаркинги:
df = pd.concat([df]*10000).sort_index() def cs(df): return df[df.groupby(level=0).a.transform('size').gt(1)] def pir(df): return df.groupby(level=0).filter(lambda x: len(x) > 1) def wen(df): s=df.a.count(level=0) return df.loc[s[s>1].index.tolist()] def jp(df): return df.loc[[i for i in df.index.get_level_values(0).unique() if len(df.loc[i]) > 1]] %timeit cs(df) # 19.5ms %timeit pir(df) # 33.8ms %timeit wen(df) # 17.0ms %timeit jp(df) # 22.3ms