Пересчет на время, связанных с ведрами
Скажем, у меня есть df, выглядящий так:
price quantity
0 100 20
1 102 31
2 105 25
3 99 40
4 104 10
5 103 20
6 101 55
Здесь нет временных интервалов. Мне нужно рассчитать средневзвешенную цену по объему для каждых 50 позиций в количестве. Каждая строка (индекс) в выходных данных будет представлять 50 единиц (в отличие от, скажем, 5-минутных интервалов), выходной столбец будет представлять собой взвешенную по объему цену.
Какой-нибудь аккуратный способ сделать это с помощью панд или numpy, если уж на то пошло?? Я попробовал использовать цикл, разделяющий каждую строку на одну цену товара, и они группируют их, как это:
def grouper(n, iterable):
it = iter(iterable)
while True:
chunk = tuple(itertools.islice(it, n))
if not chunk:
return
yield chunk
Редактировать: Вывод, который я хочу видеть на основе вышеизложенного:
vwap
0 101.20
1 102.12
2 103.36
3 101.00
Каждые 50 позиций получают новую среднюю цену.
1 ответ:
Я ударил по своей первой бите, столкнувшись с этой проблемой. Вот мое следующее появление на тарелке. Надеюсь, я смогу запустить мяч в игру и забить гол.
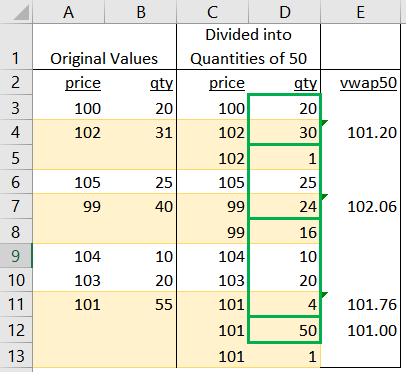
Во-первых, давайте обратимся к некоторым комментариям, связанным с ожидаемым результатом этой работы. ОП опубликовал то, что, по его мнению, результаты должны быть использованы с использованием небольших выборочных данных, которые он предоставил. Тем не менее, @user7138814 и я оба пришли к одному и тому же результату, который отличался от ОП. позвольте мне объяснить, как я считаю, что средневзвешенное значение ровно 50 единицы измерения должны быть рассчитаны на примере ОП. Я использую этот лист в качестве иллюстрации.Первые 2 столбца (A и B)являются исходными значениями, заданными ОП. учитывая эти значения, цель состоит в том, чтобы вычислить средневзвешенное значение для каждого блока ровно 50 единиц. К сожалению, эти величины не делятся равномерно на 50. Столбцы C и D показывают, как создать четные блоки по 50 единиц, разделив исходные количества по мере необходимости. Желтый цвет заштрихованные области показывают, как было разделено исходное количество, и каждая из зеленых ограниченных ячеек суммируется ровно до 50 единиц. Как только 50 единиц определены, средневзвешенное значение может быть вычислено в столбце E. Как вы можете видеть, значения в E соответствуют тому, что @user7138814 опубликовал в своем комментарии, поэтому я думаю, что мы согласны с методологией.
После долгих проб и ошибок конечным решением является функция, которая оперирует массивами numpy базовых ценовых и количественных рядов. Функция такова далее оптимизирован с помощью Numba decorator для jit-компиляции кода Python в машинный код. На моем ноутбуке он обрабатывал 3 миллиона массивов строк в секунду.Вот функция.
@numba.jit def vwap50_jit(price_col, quantity_col): n_rows = len(price_col) assert len(price_col) == len(quantity_col) qty_cumdif = 50 # cum difference of quantity to track when 50 units are reached pq = 0.0 # cumsum of price * quantity vwap50 = [] # list of weighted averages for i in range(n_rows): price, qty = price_col[i], quantity_col[i] # if current qty will cause more than 50 units # divide the units if qty_cumdif < qty: pq += qty_cumdif * price # at this point, 50 units accumulated. calculate average. vwap50.append(pq / 50) qty -= qty_cumdif # continue dividing while qty >= 50: qty -= 50 vwap50.append(price) # remaining qty and pq become starting # values for next group of 50 qty_cumdif = 50 - qty pq = qty * price # process price, qty pair as-is else: qty_cumdif -= qty pq += qty * price return np.array(vwap50)Результаты обработки выборочных данных ОП.
Обратите внимание, что я использую методOut[6]: price quantity 0 100 20 1 102 31 2 105 25 3 99 40 4 104 10 5 103 20 6 101 55 vwap50_jit(df.price.values, df.quantity.values) Out[7]: array([101.2 , 102.06, 101.76, 101. ]).valuesдля передачи массивов numpy серии pandas. Это одно из требований использования numba. Numba осознает numpy и не работает с объектами панды.Он работает довольно хорошо на 3 миллион массивов строк, создавая выходной массив из 2,25 миллиона взвешенных средних.
df = pd.DataFrame({'price': np.random.randint(95, 150, 3000000), 'quantity': np.random.randint(1, 75, 3000000)}) %timeit vwap50_jit(df.price.values, df.quantity.values) 154 ms ± 4.15 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) vwap = vwap50_jit(df.price.values, df.quantity.values) vwap.shape Out[11]: (2250037,)