Неявный оператор new и delete убивает производительность
Я бегу очень сонный профиль моего приложения и его показывает мне, что 25% и 23% времени, потраченного моей функцией делает new и delete соответственно. Я не понимаю, где это происходит. Так может кто-нибудь сказать мне, где это происходит в моем коде.
inline FixParser(fixmessage& tokenMap, const std::string& str) {
static seperator sep_delim("x01");
static seperator sep_equal("=");
static std::string error("ERROR: ");
static FixKey fix_Key;
static tokenizer token_equal(error);
static tokenizer token_delim(error);
static tokenizer::iterator itr;
token_delim.assign(str, sep_delim);
int key;
try {
for(tokenizer::iterator it = token_delim.begin();
it != token_delim.end(); ++it) {
token_equal.assign(*it, sep_equal);
itr = token_equal.begin();
key = boost::lexical_cast<int>(*itr);
if(fix_Key.keys.find(key) == fix_Key.keys.end()) continue;
++itr;
const std::string& value(*itr);
tokenMap.insert(std::pair<int, std::string>(key, value));
}
} catch(boost::bad_lexical_cast &) {
std::cerr << error << str << std::endl;
return;
}
}
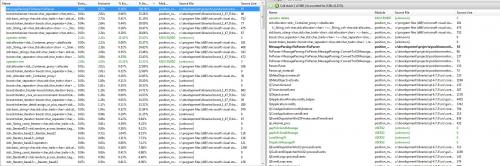
static они будут удалены позже и помещены в struct.4 ответа:
Убедитесь, что вы тестируете сборку выпуска, а не отладочную версию. Отладочные сборки используют различные версии
newиdelete, которые помогают обнаруживать утечки памяти за счет скорости, а отладочные сборки не оптимизируют много (если вообще оптимизируют).
Одно примечание: существует множество копируемых строк. Каждая строка вызовет вызов
newдля захвата памяти иdeleteдля ее освобождения.Если производительность является премией, и у вас есть возможность сохранить копию
str, Вы можете использовать индексы вместо этого. Это означает, что токены должны быть парами индексов (begin, end) вместо полноценных строк. Очевидно, что это более подвержено ошибкам.Кроме того,
tokenMapвыделяет один узел на запись в карте, если у вас есть много записей, будет много узлов (и таким образомnewсоздавать их). Вместо этого вы можете использоватьdequeи сортировать элементы, когда закончите, если вам действительно не нужно то, что предлагаетmap(автоматическая дедупликация).
Bikesheded version, удалив большинство статических переменных (не смог удержаться):
inline FixParser(fixmessage& tokenMap, const std::string& str) { static seperator sep_delim("\x01"); static seperator sep_equal("="); static FixKey const fix_Key; try { tokenizer token_delim(str, sep_delim); // avoid computing token_delim.end() at each iteration for(tokenizer::iterator it = token_delim.begin(), end = token_delim.end(); it != end; ++it) { tokenizer token_equal(*it, sep_equal); tokenizer::iterator itr = token_equal.begin(); int const key = boost::lexical_cast<int>(*itr); if(fix_Key.keys.find(key) == fix_Key.keys.end()) continue; ++itr; tokenMap.insert(std::make_pair(key, *itr)); } } catch(boost::bad_lexical_cast &) { std::cerr << error << str << std::endl; return; } }
Я бы посмотрел на
boost::lexical_cast. В своей простейшей форме он просто использует потоки. Это, вероятно, делает много ассигнований.
Проблема может заключаться в статике. Сколько раз вы вызываете функцию
FixParser?При каждом вызове объектов
token_delimиtoken_equalвызываются методы присваивания, и если они реализуются как вектор присваивания, то память, поддерживающая последовательность, будет уничтожена, а затем выделена каждый раз, когда функцияFixParserвызывается для присвоения новой записи.