Небольшая путаница со связанными списками в C
Я читаю о связанных списках и их реализации на языке Си в Википедии. Я не схватил их так быстро, как другие концепции С.
В функции list_add() Мне интересно, почему она говорит...
n->next = *p; /* the previous element (*p) now becomes the "next" element */
Я действительно не понимаю комментарий. Почему предыдущий элемент становится следующим? Разве новый узел не должен стать следующим на старом узле?
Помните, что я только начал просматривать связанные списки, поэтому медленно проведите меня по ним.
Спасибо.
Обновление
Извините, если это не было очевидно, но весь код, который я рассматриваю, находится в статье Википедии .9 ответов:
В простейшей реализации связанного списка новые узлы добавляются в начало списка, потому что это проще. Вам нужен только один указатель на первый узел списка, и вам не нужно искать по списку, чтобы найти конец. Более сложная реализация могла бы сохранить передний и конечный указатель, чтобы добавить к любому концу списка.
Поскольку список является односвязным, то есть он идет
A->B->C->etc, ему пришлось бы перебирать весь список, чтобы добавить новый элемент в конце.Вместо этого он добавляет новый элемент
nв начале и указываетn->nextна предыдущий первый элементp.
Это происходит потому, что метод добавляет новый узел в Начало списка, то есть вновь созданный узел становится новым первым узлом в списке.
Общий способ добавления нового узла в начало списка:
// allocate new node pointed by new_node and fill it. // make new node the first node by making it's next point to current head. new_node->next = head; // head should always point to the beginning of the list. head = new_node;
Функция list_addне обязательно добавляет новый узел в начало списка-она просто добавляет новый узел, который будет расположен перед
p.Аргумент
pможет косвенно указывать на узел в начале списка или любой другой узел в списке.Затем этот код создает новый узел, в котором его поле
nextустановлено на то, на что указываетp.Обновлено:
В этом коде используется указатель на узел трюк, который очень полезен при работе со связанными списками. Если вы видите связанные списки в первый раз, это может привести к путанице. Но вы должны найти время, чтобы понять это, потому что это отличный пример силы указателей.
В коде
pуказывает на указатель, который затем указывает на узел. Это означает, чтоpможет косвенно указывать на первый узел в списке:
...это означает, что
add_nodeвставит новый узел в начало списка. Ноpможет также косвенно указывать на другие узлы в списке:
Во втором примере
add_nodeвставит новый узел между первым и вторым узлами в списке.
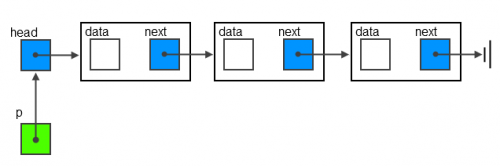
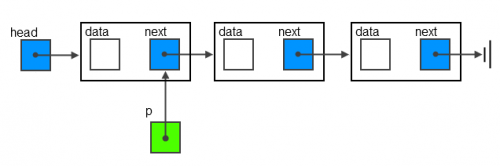
list_addфункция добавляет элемент в начало списка. Таким образом, этот комментарий означает, что наш новый элемент (n) должен указывать на старую главу списка (p):
[p]->[1]->[2] + [n] ==> [n]->[p]->[1]->[2]Новый узел должен быть следующим за старым узлом, если мы добавим элемент в конец списка:
[0]->[1]->[p] + [n] ==> [0]->[1]->[p]->[n]
Функция
list_addполучаетp, который является указателем на ссылку (указатель также), который указывает на элемент, перед которым нам нужно вставить новые данные.nявляется вновь выделенным узлом, поэтомуn->next = *p;в основном говорит: "следующее звено нового узла устанавливается для указания узла, указанного*p".... [data, next] >[data, next] > >[data, next] ... | | ^ | | | ---- | --- | | | [p] ------------------------ | [n] ------> [data, next] | | | ---------------(мы устанавливаем последнее звено, идя от [n] ->[...далее])
Комментарий в коде определенно сбивает с толку. Лучше было бы "установить следующий пункт списка нового пункта в быть пунктом, на который указала данная ссылка". Что, безусловно, чересчур многословно.
Потому что вы добавляете его в индекс, поэтому он толкнул "p" вверх на один узел, чтобы новый узел мог прорезаться в индекс предыдущего p
В связанном списке вы можете добавить свой новый узел в любом месте. Предположим, вы хотите добавить узел в начало связанного списка, вы можете сделать это с помощью n - > next=start; / / следующий новый узел указывает на первый узел start=n; / / новый узел становится первым узлом Проблема заключается в добавлении нового узла перед заданным узлом