Найти, является ли строка итеративной подстрокой?
У меня есть строка S. Как я могу найти, если строка следует за S = nT.
Примеры:
Функция должна возвращать true, если
1) S = "abab"
2) S = "abcdabcd"
3) S = "abcabcabc"
4) S = "zzxzzxzzx"
Но если S= "abcb" возвращает false.
I хотя, возможно, мы можем повторно вызвать KMP на подстроках S, а затем решить.
Например: для "abab": вызовите KMP на "a". он возвращает 2 (два экземпляра). теперь 2*лен ("а")!=len (s)
вызов на КМП на "АВ". он возвращает 2. сейчас 2 * len ("ab")==len (s) so return true
Можете ли вы предложить какие-либо лучшие алгоритмы?
8 ответов:
Я могу придумать эвристический вызов KMP только для подстроки, если Len (исходная строка)/Len of(sub string) является положительным целым числом.
Также максимальная длина подстроки должна быть меньше N / 2.
Править
Используя эти эвристики, я написал следующий код python, потому что мой C сейчас ржавый
oldstr='ABCDABCD' for i in xrange(0,len(oldstr)/2): newslice=oldstr[0:i+1] if newslice*(len(oldstr)/len(newslice)) == oldstr: print 'pattern found', newslice break
На самом деле вам нужно заботиться только о том, чтобы проверить длину подстроки, которая равна полной длине строки , деленной на простое число. Причина в следующем: если S содержит n копий T, а n не является простым, то n = ab, и поэтому S фактически также содержит копии bT (где "bT" означает "t повторяется b раз"). Это продолжение ответааниджхоу .
Обратите внимание, что при рекурсии, чтобы найти еще более короткие повторяющиеся подстроки, нам не нужно проверять всю строку опять же, только первое большее повторение-поскольку мы уже установили, что остальные большие повторения являются, Ну, повторениями первого. :)int primes[] = { 2, 3, 5, 7, 11, 13, 17 }; /* There are one or two more... ;) */ int nPrimes = sizeof primes / sizeof primes[0]; /* Passing in the string length instead of assuming ASCIIZ strings means we * don't have to modify the string in-place or allocate memory for new copies * to handle recursion. */ int is_iterative(char *s, int len) { int i, j; for (i = 0; i < nPrimes && primes[i] < len; ++i) { if (len % primes[i] == 0) { int sublen = len / primes[i]; /* Is it possible that s consists of repeats of length sublen? */ for (j = sublen; j < len; j += sublen) { if (memcmp(s, s + j, sublen)) { break; } } if (j == len) { /* All length-sublen substrings are equal. We could stop here * (meaning e.g. "abababab" will report a correct, but * non-minimal repeated substring of length 4), but let's * recurse to see if an even shorter repeated substring * can be found. */ return is_iterative(s, sublen); } } } return len; /* Could not be broken into shorter, repeated substrings */ }
Я не вижу, что алгоритм KMP помогает в этом случае. Дело не в том, чтобы решить, с чего начать следующий матч. Похоже, что один из способов сократить время поиска-начать с самой длинной возможности (половина длины) и работать вниз. Единственные длины, которые необходимо проверить, - это длины, которые равномерно делятся на общую длину. Вот пример в Ruby. Я должен добавить, что я понимаю, что вопрос был помечен как
C, но это был просто простой способ показать алгоритм I думал об этом (и позволил мне проверить, что это сработало).class String def IsPattern( ) len = self.length testlen = len / 2 # the fastest is to start with two entries and work down while ( testlen > 0 ) # if this is not an even divisor then it can't fit the pattern if ( len % testlen == 0 ) # evenly divides, so it may match if ( self == self[0..testlen-1] * ( len / testlen )) return true end end testlen = testlen - 1 end # must not have matched false end end if __FILE__ == $0 ARGV.each do |str| puts "%s, %s" % [str, str.IsPattern ? "true" : "false" ] end end [C:\test]ruby patterntest.rb a aa abab abcdabcd abcabcabc zzxzzxzzx abcd a, false aa, true abab, true abcdabcd, true abcabcabc, true zzxzzxzzx, true abcd, false
Я полагаю, вы можете попробовать следующий алгоритм:
Позволяет
Lбыть возможной длиной подстроки, которая генерирует исходное слово. ДляLот1доstrlen(s)/2проверьте, если первый символ приобретает во всехL*iпозициях дляiот 1 доstrlen(s)/L. Если это так, то это может быть возможным решением, и вы должны проверить его с помощьюmemcmp, если нет, попробуйте следующийL. Конечно, вы можете пропустить некоторые значенияL, которые не делятсяstrlen(s).
Попробуйте это:
char s[] = "abcabcabcabc"; int nStringLength = strlen (s); int nMaxCheckLength = nStringLength / 2; int nThisOffset; int nNumberOfSubStrings; char cMustMatch; char cCompare; BOOL bThisSubStringLengthRepeats; // Check all sub string lengths up to half the total length for (int nSubStringLength = 1; nSubStringLength <= nMaxCheckLength; nSubStringLength++) { // How many substrings will there be? nNumberOfSubStrings = nStringLength / nSubStringLength; // Only check substrings that fit exactly if (nSubStringLength * nNumberOfSubStrings == nStringLength) { // Assume it's going to be ok bThisSubStringLengthRepeats = TRUE; // check each character in substring for (nThisOffset = 0; nThisOffset < nSubStringLength; nThisOffset++) { // What must it be? cMustMatch = s [nThisOffset]; // check each substring's char in that position for (int nSubString = 1; nSubString < nNumberOfSubStrings; nSubString++) { cCompare = s [(nSubString * nSubStringLength) + nThisOffset]; // Don't bother checking more if this doesn't match if (cCompare != cMustMatch) { bThisSubStringLengthRepeats = FALSE; break; } } // Stop checking this substring if (!bThisSubStringLengthRepeats) { break; } } // We have found a match! if (bThisSubStringLengthRepeats) { return TRUE; } } } // We went through the whole lot, but no matches found return FALSE;
Это Java-код, но вы должны понять идею:
String str = "ababcababc"; int repPos = 0; int repLen = 0; for( int i = 0; i < str.length(); i++ ) { if( repLen == 0 ) { repLen = 1; } else { char c = str.charAt( i ); if( c == str.charAt( repPos ) ) { repPos = ++repPos % repLen; } else { repLen = i+1; } } }Это вернет длину самого короткого повторяющегося фрагмента или длину строки, если нет повторения.
Вы можете построить суффиксальный массив строки, отсортировать его.
Теперь ищите серию постоянно удваивающихся суффиксов, и когда вы достигнете одного, который будет размером со всю строку (ы), первый в серии даст вам T.Например:
abcd <-- T abcdabcd <-- S bcd bcdabcd cd cdabcd d dabcd x xzzx xzzxzzx zx zxzzx zxzzxzzx zzx <-- T zzxzzx zzxzzxzzx <-- S a apa apapa apapapa pa <-- T papa papapa <-- Another T, not detected by this algo papapapa <-- S
Подход грубой силы состоял бы в том, чтобы выбрать все возможные подстроки и посмотреть, могут ли они сформировать всю строку.
Мы можем сделать это лучше, используя наблюдение, что для подстроки, чтобы быть допустимым кандидатом
len(str) % len(substr) == 0. Это можно вывести из постановки задачи.Вот полный код:
Обратите внимание, что существует более быстрое изменение с точки зрения сложности времени, которое использует KMP.bool isRational(const string &str){ int len = str.length(); const auto &factors = getFactors(len); // this would include 1 but exclude len // sort(factors.begin(), factors.end()); To get out of the loop faster. Why? See https://stackoverflow.com/a/4698155/1043773 for(auto iter = factors.rbegin(); iter != factors.rend(); ++iter){ auto factor = *iter; bool result = true; for(int i = 0; i < factor && result; ++i){ for(int j = i + factor; j < len; j += factor, ++cntr){ if (str[i] != str[j]) { result = false; break; } } } if (result) { return true;} } return false; }Приведенный выше алгоритм является
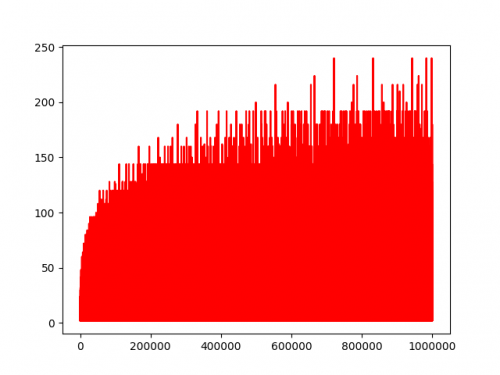
O(N * factorCount(N))Но самое хорошее в этом алгоритме то, что он может выкарабкаться гораздо быстрее, чем алгоритм KMP. Также количество факторов не сильно растет.Вот график
[i, factorCount(i)] for i <= 10^6
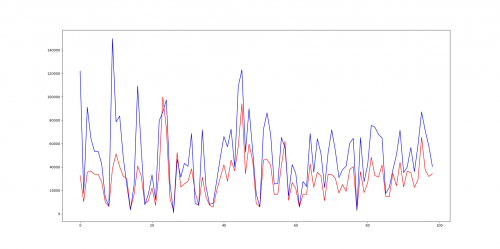
Вот как работает алгоритм по сравнению с алгоритмом KMP. красный график составляет o(Н * factorCount(Н)) и синий О(П) КМП
Код KMP выбирается из здесь