Как машина с более высокой производительностью процессора (согласно gprof) имеет худшую производительность в реальном времени?
Фон
У меня есть вычислительно интенсивная программа, которую я пытаюсь запустить на одном суперкомпьютерном узле. Вот характеристики одного из узлов суперкомпьютера:- ОС: Redhat 6 Enterprise 64-bit Процессор: Intel 2x 6-core 2.8 GHz (12 ядер) -- кэш 12MB
- ОПЕРАТИВНАЯ ПАМЯТЬ: 24 ГБ @ ???? МГц (нет доступа sudo для проверки
dmidecode)
Я также тестировал эту программу на виртуальной машине Ubuntu, работающей на моем компьютере. MacBook:
- ОС: Ubuntu 13.10 64-битная Процессор: Intel 4x 2.30 GHz (4 ядра) -- кэш 6MB
- оперативная память: 3 ГБ @1600 МГц
Программа построена с одной и той же версией gcc на обеих машинах. Однако для упрощенного тестового запуска программы Реальное время выполнения программы на суперкомпьютере значительно больше, чем на моей виртуальной машине.
Это не имело смысла для меня, и чтобы сделать его более запутанным, когда я запускаю gprof в моей программе, это показывает, что суперкомпьютер действительно быстрее, чем моя виртуальная машина. В таблице ниже показаны различные времена, которые я вижу для моей программы на каждой машине (SC = суперкомпьютер, VM = виртуальная машина):
| SC | VM |
|---------------------------|------|-------|
| Release (-O3) Real Time | 15s | 3s |
| Debug (-g -pg) Real Time | 55s | 35s |
| Debug (-g -pg) gprof Time | 6.10 | 9.24s |
Вопрос
Что происходит, что заставляет производительность суперкомпьютера в реальном времени быть хуже, когда gprof указывает на то, что производительность процессора лучше? Что я могу сделать, чтобы улучшить производительность суперкомпьютера в реальном времени?
Дополнительная Информация
Программа тратит большую часть своего времени на генерацию и решение системы линейных уравнений. Фактический решатель-это библиотека с поддержкой openmpi, которая использует отдельные потоки соответствуют количеству доступных ядер на машине. Я могу запустить отдельную тестовую программу, используя ту же библиотеку линейных решателей, которая считывает более сложную линейную систему из файла формата Matrix Market (690 МБ - Матрица " а " почти 2 миллиона квадратных метров) и решает линейную систему независимо от программы, которую я написал. В этом случае суперкомпьютер (при 48 секундах) работает быстрее, чем виртуальная машина (при 74 секундах). Это указывает мне как на то, что проблема не в линейный решатель и что проблема не связана с вводом-выводом, так как этот тест гораздо более интенсивен.Информация о процессоре
SC
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 44
model name : Intel(R) Xeon(R) CPU X5660 @ 2.80GHz
stepping : 2
cpu MHz : 2800.207
cache size : 12288 KB
physical id : 0
siblings : 6
core id : 0
cpu cores : 6
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 11
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm dca sse4_1 sse4_2 popcnt aes lahf_lm ida arat epb dts tpr_shadow vnmi flexpriority ept vpid
bogomips : 5600.41
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
processor : 1
vendor_id : GenuineIntel
cpu family : 6
model : 44
model name : Intel(R) Xeon(R) CPU X5660 @ 2.80GHz
stepping : 2
cpu MHz : 2800.207
cache size : 12288 KB
physical id : 0
siblings : 6
core id : 1
cpu cores : 6
apicid : 2
initial apicid : 2
fpu : yes
fpu_exception : yes
cpuid level : 11
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm dca sse4_1 sse4_2 popcnt aes lahf_lm ida arat epb dts tpr_shadow vnmi flexpriority ept vpid
bogomips : 5600.41
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
processor : 2
vendor_id : GenuineIntel
cpu family : 6
model : 44
model name : Intel(R) Xeon(R) CPU X5660 @ 2.80GHz
stepping : 2
cpu MHz : 2800.207
cache size : 12288 KB
physical id : 0
siblings : 6
core id : 2
cpu cores : 6
apicid : 4
initial apicid : 4
fpu : yes
fpu_exception : yes
cpuid level : 11
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm dca sse4_1 sse4_2 popcnt aes lahf_lm ida arat epb dts tpr_shadow vnmi flexpriority ept vpid
bogomips : 5600.41
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
processor : 3
vendor_id : GenuineIntel
cpu family : 6
model : 44
model name : Intel(R) Xeon(R) CPU X5660 @ 2.80GHz
stepping : 2
cpu MHz : 2800.207
cache size : 12288 KB
physical id : 0
siblings : 6
core id : 8
cpu cores : 6
apicid : 16
initial apicid : 16
fpu : yes
fpu_exception : yes
cpuid level : 11
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm dca sse4_1 sse4_2 popcnt aes lahf_lm ida arat epb dts tpr_shadow vnmi flexpriority ept vpid
bogomips : 5600.41
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
processor : 4
vendor_id : GenuineIntel
cpu family : 6
model : 44
model name : Intel(R) Xeon(R) CPU X5660 @ 2.80GHz
stepping : 2
cpu MHz : 2800.207
cache size : 12288 KB
physical id : 0
siblings : 6
core id : 9
cpu cores : 6
apicid : 18
initial apicid : 18
fpu : yes
fpu_exception : yes
cpuid level : 11
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm dca sse4_1 sse4_2 popcnt aes lahf_lm ida arat epb dts tpr_shadow vnmi flexpriority ept vpid
bogomips : 5600.41
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
processor : 5
vendor_id : GenuineIntel
cpu family : 6
model : 44
model name : Intel(R) Xeon(R) CPU X5660 @ 2.80GHz
stepping : 2
cpu MHz : 2800.207
cache size : 12288 KB
physical id : 0
siblings : 6
core id : 10
cpu cores : 6
apicid : 20
initial apicid : 20
fpu : yes
fpu_exception : yes
cpuid level : 11
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm dca sse4_1 sse4_2 popcnt aes lahf_lm ida arat epb dts tpr_shadow vnmi flexpriority ept vpid
bogomips : 5600.41
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
processor : 6
vendor_id : GenuineIntel
cpu family : 6
model : 44
model name : Intel(R) Xeon(R) CPU X5660 @ 2.80GHz
stepping : 2
cpu MHz : 2800.207
cache size : 12288 KB
physical id : 1
siblings : 6
core id : 0
cpu cores : 6
apicid : 32
initial apicid : 32
fpu : yes
fpu_exception : yes
cpuid level : 11
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm dca sse4_1 sse4_2 popcnt aes lahf_lm ida arat epb dts tpr_shadow vnmi flexpriority ept vpid
bogomips : 5599.85
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
processor : 7
vendor_id : GenuineIntel
cpu family : 6
model : 44
model name : Intel(R) Xeon(R) CPU X5660 @ 2.80GHz
stepping : 2
cpu MHz : 2800.207
cache size : 12288 KB
physical id : 1
siblings : 6
core id : 1
cpu cores : 6
apicid : 34
initial apicid : 34
fpu : yes
fpu_exception : yes
cpuid level : 11
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm dca sse4_1 sse4_2 popcnt aes lahf_lm ida arat epb dts tpr_shadow vnmi flexpriority ept vpid
bogomips : 5599.85
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
processor : 8
vendor_id : GenuineIntel
cpu family : 6
model : 44
model name : Intel(R) Xeon(R) CPU X5660 @ 2.80GHz
stepping : 2
cpu MHz : 2800.207
cache size : 12288 KB
physical id : 1
siblings : 6
core id : 2
cpu cores : 6
apicid : 36
initial apicid : 36
fpu : yes
fpu_exception : yes
cpuid level : 11
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm dca sse4_1 sse4_2 popcnt aes lahf_lm ida arat epb dts tpr_shadow vnmi flexpriority ept vpid
bogomips : 5599.85
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
processor : 9
vendor_id : GenuineIntel
cpu family : 6
model : 44
model name : Intel(R) Xeon(R) CPU X5660 @ 2.80GHz
stepping : 2
cpu MHz : 2800.207
cache size : 12288 KB
physical id : 1
siblings : 6
core id : 8
cpu cores : 6
apicid : 48
initial apicid : 48
fpu : yes
fpu_exception : yes
cpuid level : 11
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm dca sse4_1 sse4_2 popcnt aes lahf_lm ida arat epb dts tpr_shadow vnmi flexpriority ept vpid
bogomips : 5599.85
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
processor : 10
vendor_id : GenuineIntel
cpu family : 6
model : 44
model name : Intel(R) Xeon(R) CPU X5660 @ 2.80GHz
stepping : 2
cpu MHz : 2800.207
cache size : 12288 KB
physical id : 1
siblings : 6
core id : 9
cpu cores : 6
apicid : 50
initial apicid : 50
fpu : yes
fpu_exception : yes
cpuid level : 11
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm dca sse4_1 sse4_2 popcnt aes lahf_lm ida arat epb dts tpr_shadow vnmi flexpriority ept vpid
bogomips : 5599.85
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
processor : 11
vendor_id : GenuineIntel
cpu family : 6
model : 44
model name : Intel(R) Xeon(R) CPU X5660 @ 2.80GHz
stepping : 2
cpu MHz : 2800.207
cache size : 12288 KB
physical id : 1
siblings : 6
core id : 10
cpu cores : 6
apicid : 52
initial apicid : 52
fpu : yes
fpu_exception : yes
cpuid level : 11
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm dca sse4_1 sse4_2 popcnt aes lahf_lm ida arat epb dts tpr_shadow vnmi flexpriority ept vpid
bogomips : 5599.85
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
VM
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 58
model name : Intel(R) Core(TM) i7-3615QM CPU @ 2.30GHz
stepping : 9
microcode : 0x15
cpu MHz : 2294.125
cache size : 6144 KB
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts mmx fxsr sse sse2 ss syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts nopl xtopology tsc_reliable nonstop_tsc aperfmperf eagerfpu pni pclmulqdq ssse3 cx16 pcid sse4_1 sse4_2 x2apic popcnt aes xsave avx f16c rdrand hypervisor lahf_lm ida arat epb xsaveopt pln pts dtherm fsgsbase smep
bogomips : 4588.25
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
processor : 1
vendor_id : GenuineIntel
cpu family : 6
model : 58
model name : Intel(R) Core(TM) i7-3615QM CPU @ 2.30GHz
stepping : 9
microcode : 0x15
cpu MHz : 2294.125
cache size : 6144 KB
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts mmx fxsr sse sse2 ss syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts nopl xtopology tsc_reliable nonstop_tsc aperfmperf eagerfpu pni pclmulqdq ssse3 cx16 pcid sse4_1 sse4_2 x2apic popcnt aes xsave avx f16c rdrand hypervisor lahf_lm ida arat epb xsaveopt pln pts dtherm fsgsbase smep
bogomips : 4588.25
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
processor : 2
vendor_id : GenuineIntel
cpu family : 6
model : 58
model name : Intel(R) Core(TM) i7-3615QM CPU @ 2.30GHz
stepping : 9
microcode : 0x15
cpu MHz : 2294.125
cache size : 6144 KB
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts mmx fxsr sse sse2 ss syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts nopl xtopology tsc_reliable nonstop_tsc aperfmperf eagerfpu pni pclmulqdq ssse3 cx16 pcid sse4_1 sse4_2 x2apic popcnt aes xsave avx f16c rdrand hypervisor lahf_lm ida arat epb xsaveopt pln pts dtherm fsgsbase smep
bogomips : 4588.25
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
processor : 3
vendor_id : GenuineIntel
cpu family : 6
model : 58
model name : Intel(R) Core(TM) i7-3615QM CPU @ 2.30GHz
stepping : 9
microcode : 0x15
cpu MHz : 2294.125
cache size : 6144 KB
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts mmx fxsr sse sse2 ss syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts nopl xtopology tsc_reliable nonstop_tsc aperfmperf eagerfpu pni pclmulqdq ssse3 cx16 pcid sse4_1 sse4_2 x2apic popcnt aes xsave avx f16c rdrand hypervisor lahf_lm ida arat epb xsaveopt pln pts dtherm fsgsbase smep
bogomips : 4588.25
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
2 ответа:
Это, вероятно, не ответ на ваш вопрос, а скорее развернутый комментарий. Учитывая, что ни одна строка кода не показана, я могу только догадываться о природе проблемы. Система двойной розетка с системной представляет собой ccNUMA (кэш-когерентный доступ к неоднородной памяти) платформа. В системах NUMA глобальная память разделена на области, некоторые из которых являются локальными, а другие-удаленными по отношению к любому заданному ядру процессора. Доступ к локальной памяти менее затратен с точки зрения циклов памяти и обычно пропускная способность выше. Ваш MacBook имеет один разъем процессора и не является системой NUMA.
Тем не менее, очень важно включить привязку процессов и нитей (или закрепление) в системах ccNUMA. Планировщик ОС обычно старается держать все ядра процессора одинаково загруженными и поэтому постоянно перемещает потоки (процессы как коллекции потоков) вокруг. Если поток выделяет память на одном узле NUMA и затем перемещается на другой, доступ к памяти будет значительно замедлен. Этому можно было бы противостоять с помощью механизмаProcessor affinity - один предоставляет ОС список процессоров, где может работать данный поток. Фактический акт фиксации маски аффинити называется связыванием или закреплением. Привязка также важна, когда речь заходит об использовании кэша, так как перемещение потока из одного ядра в другое из того же сокета приводит к перезагрузке кэша L1 и L2, в то время как перемещение в другой сокет приводит к перезагрузке кэша L1, L2 и L3.Привязка процесса легко делается с помощью
tasksetилиnumactl. Связывание нитей является более сложным, так как оно зависит от механизма резьбы. OpenMP 4.0 стандартизирует весь процесс, но большинство реализаций OpenMP в настоящее время относятся к предыдущей эпохе (т. е. до версии 3.1), и поэтому приходится прибегать к методам, зависящим от поставщика. Для GCC / libgomp путь лежит через установкуGOMP_CPU_AFFINITY. Для вашего 12-ядерного узла кластера это должно быть сделано следующим образом:GOMP_CPU_AFFINITY="0-11" ./executableТакже OpenMP берет на себя некоторые накладные расходы и с небольшим матрицы, которые накладные расходы могут быть настолько высоки, что сводят на нет преимущества потоковой обработки. Накладные расходы растут с увеличением количества потоков тоже. Поэтому вы должны сравнить вашу программу с одинаковым количеством потоков в виртуальной машине и на узле кластера. Установка
OMP_NUM_THREADSдолжна работать для хорошо написанных OpenMP-кодов, которые не пытаются сами фиксировать количество потоков на основе какой-то внутренней логики.В резюме вы должны попробовать что-то вроде:
GOMP_CPU_AFFINITY="0-3" OMP_NUM_THREADS=4 ./executableВ обеих системах. Эта воля удалите влияние NUMA и различные накладные расходы OpenMP. Любые оставшиеся различия будут связаны с различными архитектурами кэша L3 (Ivy Bridge имеет сегментированный кэш L3, который представил Sandy Bridge), уменьшенными задержками некоторых инструкций в Ivy Bridge, различным управлением питанием (возможно, у X5660 отключен TurboBoost?), и, возможно, различные наборы инструкций, используемые библиотекой решателей, как упоминалось в @amdn.
Note3 : последнее предположение состоит в том, что суперкомпьютер имеет более быструю подсистему ввода-вывода, но не хватает скорости в матричных операциях, потому что процессор не имеет расширения AVX. MacBook медленнее делает ввод-вывод с диска, но может вычислять быстрее, потому что его процессор имеет расширение AVX. Возможно, суперкомпьютеру потребовалось 33 секунды, чтобы загрузить 690 МБ и 15 секунд, чтобы вычислить, а MacBook занял 71 секунду, чтобы загрузить 690 МБ и 3 секунды, чтобы вычислить. Это подошло бы к наблюдаемому итогу 48 секунд для суперкомпьютер и 74 секунды для MacBook.
Note2: у меня есть новая теория, я думаю, что при запуске отдельной тестовой программы и суперкомпьютер, и ваш MacBook имеют ограниченную пропускную способность памяти. Данные там составляют 690 МБ, что не помещается в кэш процессора, в то время как данные в ваших производственных запусках составляют 1,4 МБ, что действительно помещается в кэш процессора. В MacBook процессор интегрированный контроллер памяти двухканальный. На суперкомпьютере в процессор контроллер памяти процессоров Xeon X5660 включает три канала. Таким образом, для очень больших наборов данных, которые не помещаются в кэш последнего уровня процессора, суперкомпьютер будет быстрее, потому что он имеет большую пропускную способность памяти (3 против 2 каналов). Для небольших рабочих наборов, которые помещаются в кэш процессора, MacBook будет быстрее, потому что проблема становится связанной с процессором, а процессор MacBook имеет инструкции AVX, которые специализируются на линейной алгебре.
Оригинальный Ответ
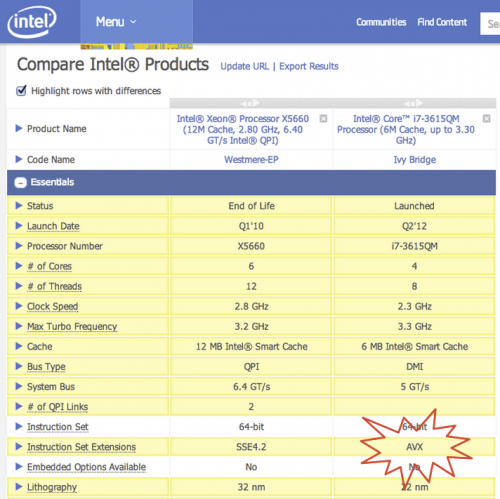
Очень вероятно, что ваша библиотека линейных решателей выбирает самую быструю процедуру на основе обнаружения во время выполнения возможностей процессора. "Суперкомпьютер" может иметь больше ядер, больше кэшей, больше памяти и работать на более высокой частоте, но у него нет инструкций Intel® Advanced Vector Extensions (Intel® AVX) , доступных в вашем MacBook. Вот обсуждение AVX для линейной алгебры
Некоторые цитаты из инженеров Intel
Недавно мы завершили серию тестов SSE против AVX на Sandy Bridge против Ivy Мост и диапазон повышения производительности был между ~3x и ~6x (для работы sqrt), а коды (C / C++) были агрессивно оптимизированы компилятором Intel C++ 13.0.0.089 ( начальный выпуск).
И это
Матричное умножение является идеальным приложением для демонстрации производительности AVX. Это сильно зависит от тайлинга для L1 locality, таким образом, возобновленный акцент на библиотеках производительности, таких как MKL.
Http://ark.intel.com/compare/47921,64900