Scrapy-как управлять файлами cookie / сессиями
Я немного запутался в том, как печенье работает с Scrapy, и как вы управляете этими печеньями.
Это в основном упрощенная версия того, что я пытаюсь сделать.: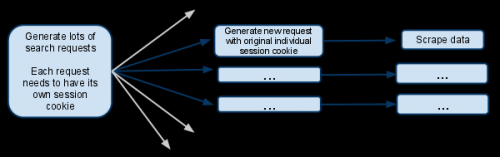
Как работает сайт:
При посещении веб-сайта вы получаете файл cookie сеанса.
Когда вы выполняете поиск, веб-сайт запоминает, что вы искали, поэтому, когда вы делаете что-то вроде перехода на следующую страницу результатов, он знает, с каким поиском он имеет дело.Мой сценарий:
У моего паука есть начальный url searchpage_url
Страница поиска запрашивается parse(), а ответ формы поиска передается в search_generator()
search_generator() затем yields множество поисковых запросов, использующих FormRequest и форму поиска ответа.
Я видел раздел документов, который говорит о мета-опции, которая останавливает слияние файлов cookie. Что это на самом деле значит? Означает ли это, что паук, который делает запрос, будет иметь свой собственный кукиехар до конца своей жизни?
Если печенье находится на уровне каждого паука, то как это работает, когда порождается несколько пауков? Можно ли заставить только первый генератор запросов порождать новых пауков и убедиться, что с тех пор только этот паук имеет дело с будущими запросами?
Я предполагаю, что должен отключить несколько одновременных запросов.. в противном случае один паук будет выполнять несколько поисков в одном и том же сеансовом файле cookie, и будущие запросы будут относиться только к самому последнему выполненному поиску?
Я в замешательстве, любое разъяснение будет очень воспринято!
Правка:
Еще один вариант, о котором я только что подумал, - это управление сеансовым файлом cookie полностью вручную и передача его от одного запроса к другому.
Я полагаю, что это означало бы отключение файлов cookie.. и затем захват файла cookie сеанса из поискового ответа и передача его каждому последующему запросу.
Это то, что вы должны делать в этой ситуации?4 ответа:
Три года спустя, я думаю, это именно то, что вы искали.: http://doc.scrapy.org/en/latest/topics/downloader-middleware.html#std:reqmeta-cookiejar
Просто используйте что-то вроде этого в методе start_requests вашего паука:
for i, url in enumerate(urls): yield scrapy.Request("http://www.example.com", meta={'cookiejar': i}, callback=self.parse_page)И помните, что для последующих запросов вам нужно явно присоединять cookiejar каждый раз:
def parse_page(self, response): # do some processing return scrapy.Request("http://www.example.com/otherpage", meta={'cookiejar': response.meta['cookiejar']}, callback=self.parse_other_page)
from scrapy.http.cookies import CookieJar ... class Spider(BaseSpider): def parse(self, response): '''Parse category page, extract subcategories links.''' hxs = HtmlXPathSelector(response) subcategories = hxs.select(".../@href") for subcategorySearchLink in subcategories: subcategorySearchLink = urlparse.urljoin(response.url, subcategorySearchLink) self.log('Found subcategory link: ' + subcategorySearchLink), log.DEBUG) yield Request(subcategorySearchLink, callback = self.extractItemLinks, meta = {'dont_merge_cookies': True}) '''Use dont_merge_cookies to force site generate new PHPSESSID cookie. This is needed because the site uses sessions to remember the search parameters.''' def extractItemLinks(self, response): '''Extract item links from subcategory page and go to next page.''' hxs = HtmlXPathSelector(response) for itemLink in hxs.select(".../a/@href"): itemLink = urlparse.urljoin(response.url, itemLink) print 'Requesting item page %s' % itemLink yield Request(...) nextPageLink = self.getFirst(".../@href", hxs) if nextPageLink: nextPageLink = urlparse.urljoin(response.url, nextPageLink) self.log('\nGoing to next search page: ' + nextPageLink + '\n', log.DEBUG) cookieJar = response.meta.setdefault('cookie_jar', CookieJar()) cookieJar.extract_cookies(response, response.request) request = Request(nextPageLink, callback = self.extractItemLinks, meta = {'dont_merge_cookies': True, 'cookie_jar': cookieJar}) cookieJar.add_cookie_header(request) # apply Set-Cookie ourselves yield request else: self.log('Whole subcategory scraped.', log.DEBUG)
Я думаю, что самым простым подходом было бы запустить несколько экземпляров одного и того же spider, используя поисковый запрос в качестве аргумента spider (который будет получен в конструкторе), чтобы повторно использовать функцию управления файлами cookie Scrapy. Таким образом, у вас будет несколько экземпляров spider, каждый из которых будет сканировать один конкретный поисковый запрос и его результаты. Но вам нужно запустить пауков самостоятельно с помощью:
scrapy crawl myspider -a search_query=somethingИли вы можете использовать Scrapyd для запуска всех пауков через API JSON.