scikits.изучите методы кластеризации для параметров подгонки кривой
Я хотел бы получить некоторые предложения по наилучшей методике кластеризации, которая будет использоваться, используя python и scikits.учить. Наши данные получены из микрочипа фенотипа , который измеряет активность метаболизма клетки на различных субстратах с течением времени. Выходные данные представляют собой серию сигмовидных кривых, для которых мы извлекаем ряд параметров кривой через подгонку к сигмовидной функции.
Мы хотели бы "ранжировать" эти кривые активности с помощью кластеризации, используя фиксированное число кассет. На данный момент мы используем алгоритм k-means, предоставленный пакетом, с (init='random', k=10, n_init=100, max_iter=1000). Входной сигнал представляет собой матрицу с n_samples и 5 параметрами для каждого образца. Количество образцов может варьироваться, но обычно оно составляет около нескольких тысяч (т. е. Кластеризация кажется эффективной и действенной, но я был бы признателен за любые предложения относительно различных методов или наилучшего способа оценки качества кластеризации.
Здесь пара диаграммы, которые могут помочь:
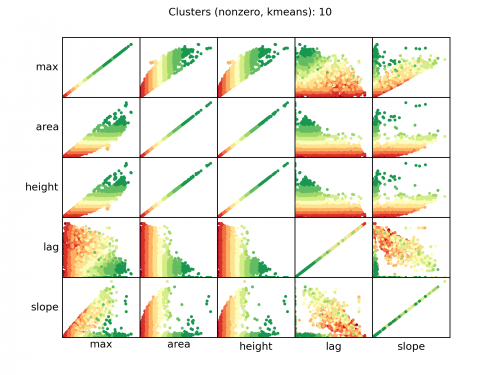
Диаграмма рассеяния входных параметров (некоторые из них достаточно коррелированы), цвет отдельных выборок относительно присвоенного кластера.
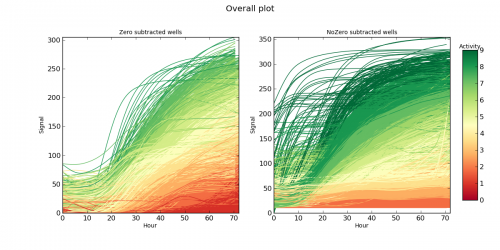
Сигмовидные кривые, из которых были извлечены входные параметры, цвет которых соответствует назначенному кластеру.
EDIT
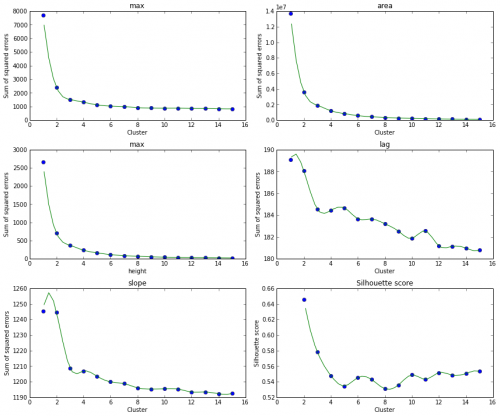
Ниже некоторых графиков локтя и оценка силуэта для каждого числа кластера.
2 ответа:
Заметили ли вы полосатый узор на ваших участках?
Это означает, что вы недостаточно хорошо нормализовали свои данные.
"площадь" и "высота" сильно коррелируют и, вероятно, в наибольшем масштабе. Все скопления происходили на этой оси.
Вы абсолютно обязаны:
- выполнить тщательную предварительную обработку
- Убедитесь, что ваши функции расстояния создают значимое (для вас, а не только для компьютера) понятие подобия
- реальность-проверьте свою результаты, и проверить, что они не слишком просты, определяемые, например, одним атрибутом
Не следуйте слепо за числами . K-means с радостью создаст k кластеров независимо от того, какие данные вы дадите. Он просто оптимизирует какое-то число. Вы должны проверить, что результаты полезны, и проанализировать их смысловое значение - и вполне может быть, что это просто математически локальный оптимум, но бессмысленный для вашей задачи.
Для 5000 образцов все методы должны работать без проблем. Это довольно хороший обзор здесь. Одна вещь, которую нужно рассмотреть, - это то, хотите ли вы зафиксировать количество кластеров или нет. Смотрите таблицу для возможных вариантов алгоритма кластеризации в зависимости от этого.
Я думаю, что спектральная кластеризация-довольно хороший метод. Вы можете использовать его, например, вместе с ядром RBF. Однако вам придется настроить гамму и, возможно, ограничить подключение.
Выбор, который не делает нужны n_clusters WARD и DBSCAN, также солидный выбор. Вы также можете ознакомиться сэтой диаграммой моего личного мнения , на которую я не могу найти ссылку в scikit-learn docs...
Для оценки результата: если у вас нет какой-либо основной истины (которой, я полагаю, у вас нет, если это исследование), нет хорошей меры [пока] (в scikit-learn).
Существует одна неконтролируемая мера, Оценка силуэта , но afaik, которая благоприятствует очень компактным кластерам, найденным к-значит. Существуют меры стабильности для кластеров, которые могут помочь, хотя они еще не реализованы в sklearn.
Лучше всего было бы найти хороший способ проверить данные и визуализировать кластеризацию. Вы пробовали СПС и думали о различных методах обучения?