Случайность-это едва ли случайность вообще?
Я сделал это, чтобы проверить случайность randint:
>>> from random import randint
>>>
>>> uniques = []
>>> for i in range(4500): # You can see I was optimistic.
... x = randint(500, 5000)
... if x in uniques:
... raise Exception('We duped %d at iteration number %d' % (x, i))
... uniques.append(x)
...
Traceback (most recent call last):
File "<stdin>", line 4, in <module>
Exception: We duped 887 at iteration number 7
я попробовал примерно в 10 раз больше, и лучший результат, который я получил, был 121 итераций перед повторителем. Это лучший результат, который вы можете получить из стандартной библиотеки?
11 ответов:
парадокс дня рождения, или почему PRNGs производят дубликаты чаще, чем вы могли бы подумать.
есть несколько проблем в игре в проблеме OP. Один из них парадокс дней рождения как уже упоминалось выше, и второе-это природа того, что вы генерируете, что по своей сути не гарантирует, что данное число не будет повторяться.парадокс дня рождения применяется, когда данное значение может произойти более одного раза в течение периода генератор-и поэтому дубликаты могут происходить в пределах выборки значений. Эффект парадокса дней рождения состоит в том, что реальная вероятность получения таких повторов довольно существенная, а средний период между ними меньше, чем можно было подумать. Этот диссонанс между перцептивными и фактическими вероятностями делает парадокс дня рождения хорошим примером примера a когнитивное искажение, где наивная интуитивная оценка, вероятно, будет дико неправильный.
быстрый праймер на генераторах псевдослучайных чисел (PRNGs)
первая часть вашей проблемы заключается в том, что вы принимаете выставленное значение генератора случайных чисел и превращение их в гораздо меньшем количестве, поэтому пространство возможных значений уменьшается. Хотя некоторые генераторы псевдослучайных чисел Не повторяйте значения в течение их периода это преобразование изменяет домен на гораздо меньший. Чем меньше домен делает недействительным условие "нет повторов", так что вы можете ожидать значительную вероятность повторений.
некоторые алгоритмы, такие как линейный конгруэнтный PRNG (
A'=AX|M) do гарантия уникальности на весь период. В LCG генерируемое значение содержит все состояние аккумулятора, и никакое дополнительное состояние не удерживается. Генератор является детерминированным и не может повторять число в течение периода - любое заданное значение аккумулятора может означать только одно возможно последовательное значение. Поэтому каждое значение может возникать только один раз в течение периода работы генератора. Однако период такого PRNG относительно невелик-около 2^30 для типичных реализаций алгоритма LCG-и не может быть больше, чем число различных значений.не все алгоритмы PRNG разделяют эту характеристику; некоторые могут повторять заданное значение в течение периода. В задаче ОП Мерсенн Твистер алгоритм (используется в Python случайные модуль) имеет очень длительный период - гораздо больше, чем 2^32. В отличие от линейного конгруэнтного PRNG, результат не является чисто функцией предыдущего выходного значения, поскольку аккумулятор содержит дополнительное состояние. С 32-битным целочисленным выходом и периодом ~2^19937 он не может обеспечить такую гарантию.
Mersenne Twister является популярным алгоритмом для PRNGs, потому что он имеет хорошие статистические и геометрические свойства и очень длительный период - желательно характеристики для PRNG используются на имитационных моделях.
хороший статистические свойства означает, что числа, генерируемые алгоритмом равномерно распределены без чисел, имеющих значительно более высокую вероятность появления, чем другие. Плохие статистические свойства могут привести к нежелательному перекосу в результатах.
хороший геометрические свойства означает, что множества из N чисел не лежат на гиперплоскости в n-мерном пространстве. Плохие геометрические свойства могут создавать ложные корреляции в имитационной модели и искажать результаты.
длительный период означает, что вы можете генерировать много чисел, прежде чем последовательность обернется к началу. Если модель нуждается в большом количестве итераций или должна выполняться из нескольких семян, то 2^30 или около того дискретных чисел, доступных из типичной реализации LCG, может быть недостаточно. Алгоритм MT19337 имеет очень длинный период-2^19337-1, или около 10^5821. По сравнению с Общее число атомов во Вселенной оценивается примерно в 10^80.
32-разрядное целое число, полученное с помощью MT19337 PRNG, не может представлять достаточно дискретных значений, чтобы избежать повторения в течение такого большого периода. В этом случае дублирование значений, скорее всего, произойдет и неизбежно с достаточно большой выборкой.
парадокс дня рождения в двух словах
эту проблему первоначально определяется как вероятность того, что любые два человека в комнате разделяют один и тот же день рождения. Ключевым моментом является то, что двумя люди в комнате могли бы разделить день рождения. Люди склонны наивно неверно интерпретировать проблему как вероятность того, что кто-то в комнате разделяет день рождения с конкретным человеком, который является источником когнитивное искажение это часто заставляет людей недооценивать вероятность. Это неверное предположение - нет требования, чтобы матч был для конкретного человека, и любые два человека могут соответствовать.
вероятность совпадения, происходящего между любыми двумя людьми, намного выше, чем вероятность совпадения с конкретным человеком, поскольку совпадение не обязательно должно быть до определенной даты. Скорее, вам нужно только найти двух человек, которые разделяют один и тот же день рождения. Из этого графика (который можно найти на странице Википедии по этому вопросу), мы видим, что нам нужно только 23 человека в комнате, чтобы быть 50% шанс найти два, которые соответствуют таким образом.
С Wikipedia запись на эту тему мы можем получить хорошее резюме. в проблеме OP у нас есть 4500 возможных "дней рождения", а не 365. Для заданного числа генерируемых случайных величин (приравниваемых к "людям") мы хотим знать вероятность любой два одинаковых значения, входящие в последовательность.
вычисление вероятного эффекта парадокса дня рождения на проблему OP
для последовательности из 100 чисел у нас есть (100 * 99) / 2 = 4950 http://mathurl.com/yc4cdsr.png пар (см. понимание проблемы), которые потенциально могут совпадать (т. е. первый может совпадать со вторым, третьим и т. д., второй может соответствовать третьему, четвертому и т. д. и так далее), поэтому число комбинации что может потенциально матч гораздо больше, чем просто 100.
С вычисление вероятности мы получаем выражение 1 - (4500! / (4500**100 * (4500 - 100)!) http://mathurl.com/ybfweny.png. следующий фрагмент кода Python ниже делает наивную оценку вероятности возникновения совпадающей пары.
# === birthday.py =========================================== # from math import log10, factorial PV=4500 # Number of possible values SS=100 # Sample size # These intermediate results are exceedingly large numbers; # Python automatically starts using bignums behind the scenes. # numerator = factorial (PV) denominator = (PV ** SS) * factorial (PV - SS) # Now we need to get from bignums to floats without intermediate # values too large to cast into a double. Taking the logs and # subtracting them is equivalent to division. # log_prob_no_pair = log10 (numerator) - log10 (denominator) # We've just calculated the log of the probability that *NO* # two matching pairs occur in the sample. The probability # of at least one collision is 1.0 - the probability that no # matching pairs exist. # print 1.0 - (10 ** log_prob_no_pair)это дает разумный вид результат p=0,669 на матч в пределах 100 числа, отобранные из совокупности 4500 возможных значений. (Может быть, кто-то может проверить это и оставить комментарий, если это неправильно). Из этого мы видим, что длины пробегов между совпадающими числами, наблюдаемыми OP, кажутся вполне разумными.
сноска: использование перетасовки для получения уникальной последовательности псевдослучайных чисел
посмотреть этот ответ ниже от S. Mark для получения гарантированного уникального набора случайных чисел. Техника, к которой относится плакат, берет массив чисел (которые вы предоставляете, чтобы вы могли сделать их уникальными) и перемешивает их в случайном порядке. Рисование чисел в последовательности из перетасованного массива даст вам последовательность псевдослучайных чисел, которые гарантированно не повторятся.
Сноска: Криптографически Безопасный PRNGs
алгоритм MT не криптографически защищенного поскольку относительно легко сделать вывод о внутреннем состояние генератора путем наблюдения последовательности чисел. Другие алгоритмы, такие как Блюм Блюм Шуб используются для криптографических приложений, но могут быть непригодны для моделирования или общих приложений случайных чисел. Криптографически защищенные PRNGs могут быть дорогими (возможно, требующими вычислений bignum) или не иметь хороших геометрических свойств. В случае этого типа алгоритма основное требование состоит в том, что он должен быть вычислительно неосуществимым для вывода внутреннее состояние генератора путем наблюдения за последовательностью значений.

прежде чем обвинять Python, вы должны действительно освежить некоторую теорию вероятности и статистики. Начните с чтения о парадокс дней рождения
кстати, the
randomмодуль в Python использует Мерсенн твистер PRNG, который считается очень хорошим, имеет огромный период и был тщательно протестирован. Так что будьте уверены, что вы в хороших руках.
Если вы не хотите repetative один, генерировать последовательный массив и использовать случайные.перемешать

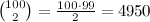{kind=link}
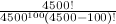{kind=link}
истинная случайность определенно включает повторение значений до того, как весь набор возможных значений будет исчерпан. Иначе это не было бы случайным, так как вы могли бы предсказать, как долго значение не будет повторяться.
Если вы когда-нибудь бросали кости, вы наверняка получили 3 шестерки в ряд довольно часто...
Это не репитер. Повторитель - это когда вы повторяете одно и то же последовательность. Не просто один номер.
создания
4500случайные числа из диапазона500 <= x <= 5000. Затем вы проверяете, чтобы увидеть для каждого номера, был ли он создан раньше. Элемент проблема с Днем рождения говорит нам, какова вероятность того, что два из этих чисел совпадут с заданнымnпытается выйти из диапазонаd.вы также можете инвертировать формулу, чтобы вычислить, сколько чисел вам нужно сгенерировать, пока вероятность создания дубликата не будет больше
50%. В этом случае у вас есть>50%шанс найти дубликат номера после79итераций.
вы определили случайное пространство из 4501 значения (500-5000), и вы повторяете 4500 раз. Вы в основном гарантированно получите столкновение в тесте, который вы написали.
чтобы думать об этом по-другому:
- когда результирующий массив пуст P (dupe) = 0
- 1 значение в массиве P (dupe) = 1/4500
- 2 значения в массиве P (dupe) = 2/4500
- etc.
Так что к тому времени, когда вы доберетесь до 45/4500, эта вставка имеет 1% шанс быть дубликатом, и эта вероятность продолжает увеличиваться с каждой последующей вставкой.
чтобы создать тест, который действительно проверяет способности случайной функции, увеличьте вселенную возможных случайных значений (например: 500-500000), вы можете или не можете получить обман. Но в среднем вы получите гораздо больше итераций.
есть парадокс дня рождения. Принимая это во внимание, вы понимаете, что то, что вы говорите, - это поиск "764, 3875, 4290, 4378, 764" или что-то вроде этого не очень случайно, потому что число в этой последовательности повторяется. Истинный способ сделать это-это сравнить последовательности друг с другом. Для этого я написал скрипт python.
from random import randint y = 21533456 uniques = [] for i in range(y): x1 = str(randint(500, 5000)) x2 = str(randint(500, 5000)) x3 = str(randint(500, 5000)) x4 = str(randint(500, 5000)) x = (x1 + ", " + x2 + ", " + x3 + ", " + x4) if x in uniques: raise Exception('We duped the sequence %d at iteration number %d' % (x, i)) else: raise Exception('Couldn\'t find a repeating sequence in %d iterations' % (y)) uniques.append(x)