Отображение значений, которые не заканчиваются на ".0" Питон Панды
У меня есть столбец float, который содержит значения NaN и значения float. Как отфильтровать те значения, которые не заканчиваются на .0?
Например:
Col1
0.7
1.0
1.1
9.0
9.5
NaN
Результат желания будет:
Col1
0.7
1.1
9.2
3 ответа:
Вы можете использовать
boolean indexing:#convert to string and compare last value print ((df.Col1.astype(str).str[-1] != '0') & (df.Col1.notnull())) 0 True 1 False 2 True 3 False 4 True 5 False Name: Col1, dtype: bool print (df[(df.Col1.astype(str).str[-1] != '0') & (df.Col1.notnull())]) Col1 0 0.7 2 1.1 4 9.5Еще одно решение для сравнения преобразованного значения с
ìnt, но сначала нужноfillna:s = df.Col1.fillna(1) print (df[s.astype(int) != s]) Col1 0 0.7 2 1.1 4 9.5Тайминги :
#[30000 rows x 1 columns] df = pd.concat([df]*10000).reset_index(drop=True) def jez2(df): s = df.Col1.fillna(1) return (df[s.astype(int) != s]) In [179]: %timeit (df[(df.Col1.astype(str).str[-1] != '0') & (df.Col1.notnull())]) 10 loops, best of 3: 80.2 ms per loop In [180]: %timeit (jez2(df)) 1000 loops, best of 3: 1.16 ms per loop In [181]: %timeit (df[df.Col1 // 1 != df.Col1].dropna()) 100 loops, best of 3: 3.04 ms per loop In [182]: %timeit (df[df['Col1'].mod(1) > 0].dropna()) 100 loops, best of 3: 2.58 ms per loop
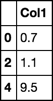
Другой метод заключается в использовании
mod(1)для вычисления модуля с 1:Здесь мы видим эффектIn [60]: df[df['Col1'].mod(1) > 0].dropna() Out[60]: Col1 0 0.7 2 1.1 4 9.5mod, целые числа становятся0, а дробные части остаются:In [62]: df['Col1'].mod(1) Out[62]: 0 0.7 1 0.0 2 0.1 3 0.0 4 0.5 5 NaN Name: Col1, dtype: float64