как использовать очень большое (>2 м) слово, вложенное в tensorflow?
Я запускаю модель с очень большим вложением слов (>2M слов). Когда я использую tf.embedding_lookup, он ожидает матрицу, которая является большой. Когда я бегу, я впоследствии получаю из GPU ошибку памяти. Если я уменьшу размер встраивания, все будет работать нормально.
Есть ли способ справиться с большим вложением?
1 ответ:
Рекомендуется использовать разделитель , чтобы разделить этот большой тензор на несколько частей:
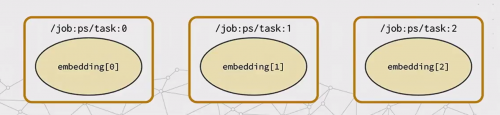
Это разделит тензор на 3 фрагмента вдоль оси 0, но остальная часть программы будет видеть его как обычный тензор. Самое большое преимущество заключается в использовании разделителя вместе с параметром репликации сервера , например:embedding = tf.get_variable("embedding", [1000000000, 20], partitioner=tf.fixed_size_partitioner(3))with tf.device(tf.train.replica_device_setter(ps_tasks=3)): embedding = tf.get_variable("embedding", [1000000000, 20], partitioner=tf.fixed_size_partitioner(3))Ключевой функцией здесь является
tf.train.replica_device_setter. Он позволяет запускать 3 различных процесса, называемых параметр серверы, в нем хранятся все переменные модели. Большой тензорembeddingбудет разбит на эти серверы, как на этой картинке.