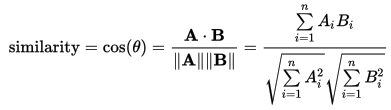Эффективное Нахождение Ближайшего Слова В Вложении Тензорного Потока
В последнее время я пытаюсь найти наиболее близкое слово к вложению. Два наиболее заметных способа сделать это-с помощью косинусного расстояния или евклидова расстояния.
Я пытаюсь найти, как эффективно вычислить косинусное расстояние для тензора формы[batch_size x embedding_size]
Один из подходов состоит в том, чтобы распаковать Тензор и вычислить косинусное расстояние
#embedding is shape [vocab_size x embedding size]
array_list = tf.unpack(batch_array)
word_class_list = tf.unpack(embedding)
index_list_of_closest_word = []
for eacharray in array_list:
list_of_distances = []
for eachwordclass in word_class_list:
list_of_distances.append(cosine_distance(eacharray, eachwordclass))
index_list_of_closest_word.append(tf.argmax(tf.pack(list_of_distances)))
Однако такой подход является ужасно неэффективной. Может быть, есть более эффективный способ сделать это? Я знаю, что word2vec делает это довольно быстрый и tensorflow, с мощностью графического процессора, должен быть в состоянии делать эти пакетные вычисления параллельно.
Спасибо!
1 ответ:
Формула косинусного подобия является:
Входные данные, которые у вас есть:
embedding: матрица вложения формы[vocab_size, embedding_size]batch_array: пакет вложений, к которому вы хотите найти наиболее близкие слова, формы[batch_size, embedding_size]embedding = tf.placeholder(tf.float32, [vocab_size, embedding_size]) batch_array = tf.placeholder(tf.float32, [batch_size, embedding_size])
Чтобы вычислить косинусное сходство, вы можете сначала L2 нормализовать оба входа:
(возможно, вы захотите сохранить нормированное вложение , поскольку вы собираетесь использовать его повторно. лот)normed_embedding = tf.nn.l2_normalize(embedding, dim=1) normed_array = tf.nn.l2_normalize(batch_array, dim=1)Затем вы должны вычислить точечные произведения всех слов (
vocab_sizeвсего) против всех массивов из пакета (batch_sizeвсего):cosine_similarity = tf.matmul(normed_array, tf.transpose(normed_embedding, [1, 0]))Вы можете, наконец, вычислить argmax для каждого элемента пакета:
closest_words = tf.argmax(cosine_similarity, 1) # shape [batch_size], type int64