Советы по работе с неоднозначным оператором в грамматике ANTLR 4
Я пишу файл грамматики antlr для диалекта basic. Большинство из них либо работают, либо у меня есть хорошее представление о том, что мне нужно делать дальше. Однако я совсем не уверен, что мне следует делать с символом'=', который используется как для тестов на равенство, так и для задания.
Например, это допустимое утверждение
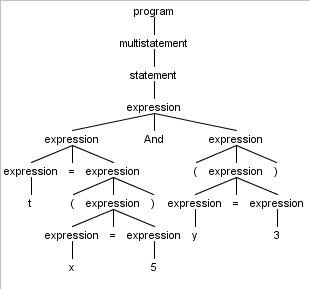
t = (x = 5) And (y = 3)
Это вычисляет, если x равно 5, если y равно 3, то выполняет логическое и на этих результатах и присваивает результат t.
Моя грамматика разберем это; пусть и неверно, но я думаю, что разрешится само собой, как только разрешится двусмысленность .
Как я различаю два вида использования символа'='?
1) Должен ли я удалить правило присваивания из выражения и обрабатывать эти случаи (тест присваивания против равенства) в моей реализации посетителя и или слушателя во время генерации кода
2) есть ли лучший способ определить грамматику таким образом, что она уже отсортирована
Бы кто-то сможет просто указать мне в правильном направлении, как лучше всего реализовать эту языковую "особенность"?
Кроме того, я читал окончательное руководство по ANTLR4, а также Шаблоны языковой реализации, ища решение для этого. Она может быть там, но я еще не нашел ее.
Ниже приведена полная грамматика синтаксического анализатора. В настоящее время маркер ASSIGN имеет значение '='. Равное значение '=='.
parser grammar wlParser;
options { tokenVocab=wlLexer; }
program
: multistatement (NEWLINE multistatement)* NEWLINE?
;
multistatement
: statement (COLON statement)*
;
statement
: declarationStat
| defTypeStat
| assignment
| expression
;
assignment
: lvalue op=ASSIGN expression
;
expression
: <assoc=right> left=expression op=CARAT right=expression #exponentiationExprStat
| (PLUS|MINUS) expression #signExprStat
| IDENTIFIER DATATYPESUFFIX? LPAREN expression RPAREN #arrayIndexExprStat
| left=expression op=(ASTERISK|FSLASH) right=expression #multDivExprStat
| left=expression op=BSLASH right=expression #integerDivExprStat
| left=expression op=KW_MOD right=expression #modulusDivExprStat
| left=expression op=(PLUS|MINUS) right=expression #addSubExprStat
| left=string op=AMPERSAND right=string #stringConcatenation
| left=expression op=(RELATIONALOPERATORS | KW_IS | KW_ISA) right=expression #relationalComparisonExprStat
| left=expression (op=LOGICALOPERATORS right=expression)+ #logicalOrAndExprStat
| op=KW_LIKE patternString #likeExprStat
| LPAREN expression RPAREN #groupingExprStat
| NUMBER #atom
| string #atom
| IDENTIFIER DATATYPESUFFIX? #atom
;
lvalue
: (IDENTIFIER DATATYPESUFFIX?) | (IDENTIFIER DATATYPESUFFIX? LPAREN expression RPAREN)
;
string
: STRING
;
patternString
: DQUOT (QUESTIONMARK | POUND | ASTERISK | LBRACKET BANG? .*? RBRACKET)+ DQUOT
;
referenceType
: DATATYPE
;
declarationStat
: constDecl
| varDecl
;
constDecl
: CONSTDECL? KW_CONST IDENTIFIER EQUAL expression
;
varDecl
: VARDECL (varDeclPart (COMMA varDeclPart)*)? | listDeclPart
;
varDeclPart
: IDENTIFIER DATATYPESUFFIX? ((arrayBounds)? KW_AS DATATYPE (COMMA DATATYPE)*)?
;
listDeclPart
: IDENTIFIER DATATYPESUFFIX? KW_LIST KW_AS DATATYPE
;
arrayBounds
: LPAREN (arrayDimension (COMMA arrayDimension)*)? RPAREN
;
arrayDimension
: INTEGER (KW_TO INTEGER)?
;
defTypeStat
: DEFTYPES DEFTYPERANGE (COMMA DEFTYPERANGE)*
;
Это грамматика лексера.
lexer grammar wlLexer;
NUMBER
: INTEGER
| REAL
| BINARY
| OCTAL
| HEXIDECIMAL
;
RELATIONALOPERATORS
: EQUAL
| NEQUAL
| LT
| LTE
| GT
| GTE
;
LOGICALOPERATORS
: KW_OR
| KW_XOR
| KW_AND
| KW_NOT
| KW_IMP
| KW_EQV
;
INSTANCEOF
: KW_IS
| KW_ISA
;
CONSTDECL
: KW_PUBLIC
| KW_PRIVATE
;
DATATYPE
: KW_BOOLEAN
| KW_BYTE
| KW_INTEGER
| KW_LONG
| KW_SINGLE
| KW_DOUBLE
| KW_CURRENCY
| KW_STRING
;
VARDECL
: KW_DIM
| KW_STATIC
| KW_PUBLIC
| KW_PRIVATE
;
LABEL
: IDENTIFIER COLON
;
DEFTYPERANGE
: [a-zA-Z] MINUS [a-zA-Z]
;
DEFTYPES
: KW_DEFBOOL
| KW_DEFBYTE
| KW_DEFCUR
| KW_DEFDBL
| KW_DEFINT
| KW_DEFLNG
| KW_DEFSNG
| KW_DEFSTR
| KW_DEFVAR
;
DATATYPESUFFIX
: PERCENT
| AMPERSAND
| BANG
| POUND
| AT
| DOLLARSIGN
;
STRING
: (DQUOT (DQUOTESC|.)*? DQUOT)
| (LBRACE (RBRACEESC|.)*? RBRACE)
| (PIPE (PIPESC|.|NEWLINE)*? PIPE)
;
fragment DQUOTESC: '""' ;
fragment RBRACEESC: '}}' ;
fragment PIPESC: '||' ;
INTEGER
: DIGIT+ (E (PLUS|MINUS)? DIGIT+)?
;
REAL
: DIGIT+ PERIOD DIGIT+ (E (PLUS|MINUS)? DIGIT+)?
;
BINARY
: AMPERSAND B BINARYDIGIT+
;
OCTAL
: AMPERSAND O OCTALDIGIT+
;
HEXIDECIMAL
: AMPERSAND H HEXDIGIT+
;
QUESTIONMARK: '?' ;
COLON: ':' ;
ASSIGN: '=';
SEMICOLON: ';' ;
AT: '@' ;
LPAREN: '(' ;
RPAREN: ')' ;
DQUOT: '"' ;
LBRACE: '{' ;
RBRACE: '}' ;
LBRACKET: '[' ;
RBRACKET: ']' ;
CARAT: '^' ;
PLUS: '+' ;
MINUS: '-' ;
ASTERISK: '*' ;
FSLASH: '/' ;
BSLASH: '\' ;
AMPERSAND: '&' ;
BANG: '!' ;
POUND: '#' ;
DOLLARSIGN: '$' ;
PERCENT: '%' ;
COMMA: ',' ;
APOSTROPHE: ''' ;
TWOPERIODS: '..' ;
PERIOD: '.' ;
UNDERSCORE: '_' ;
PIPE: '|' ;
NEWLINE: 'rn' | 'r' | 'n';
EQUAL: '==' ;
NEQUAL: '<>' | '><' ;
LT: '<' ;
LTE: '<=' | '=<';
GT: '>' ;
GTE: '=<'|'<=' ;
KW_AND: A N D ;
KW_BINARY: B I N A R Y ;
KW_BOOLEAN: B O O L E A N ;
KW_BYTE: B Y T E ;
KW_DATATYPE: D A T A T Y P E ;
KW_DATE: D A T E ;
KW_INTEGER: I N T E G E R ;
KW_IS: I S ;
KW_ISA: I S A ;
KW_LIKE: L I K E ;
KW_LONG: L O N G ;
KW_MOD: M O D ;
KW_NOT: N O T ;
KW_TO: T O ;
KW_FALSE: F A L S E ;
KW_TRUE: T R U E ;
KW_SINGLE: S I N G L E ;
KW_DOUBLE: D O U B L E ;
KW_CURRENCY: C U R R E N C Y ;
KW_STRING: S T R I N G ;
fragment BINARYDIGIT: ('0'|'1') ;
fragment OCTALDIGIT: ('0'|'1'|'2'|'3'|'4'|'5'|'6'|'7') ;
fragment DIGIT: '0'..'9' ;
fragment HEXDIGIT: ('0'|'1'|'2'|'3'|'4'|'5'|'6'|'7'|'8'|'9' | A | B | C | D | E | F) ;
fragment A: ('a'|'A');
fragment B: ('b'|'B');
fragment C: ('c'|'C');
fragment D: ('d'|'D');
fragment E: ('e'|'E');
fragment F: ('f'|'F');
fragment G: ('g'|'G');
fragment H: ('h'|'H');
fragment I: ('i'|'I');
fragment J: ('j'|'J');
fragment K: ('k'|'K');
fragment L: ('l'|'L');
fragment M: ('m'|'M');
fragment N: ('n'|'N');
fragment O: ('o'|'O');
fragment P: ('p'|'P');
fragment Q: ('q'|'Q');
fragment R: ('r'|'R');
fragment S: ('s'|'S');
fragment T: ('t'|'T');
fragment U: ('u'|'U');
fragment V: ('v'|'V');
fragment W: ('w'|'W');
fragment X: ('x'|'X');
fragment Y: ('y'|'Y');
fragment Z: ('z'|'Z');
IDENTIFIER
: [a-zA-Z_][a-zA-Z0-9_~]*
;
LINE_ESCAPE
: (' ' | 't') UNDERSCORE ('r'? | 'n')
;
WS
: [ t] -> skip
;
1 ответ:
Взгляните на эту грамматику (обратите внимание, что эта грамматика не должна быть грамматикой для BASIC, это просто пример, чтобы показать, как устранить двусмысленность, используя " = " как для присваивания, так и для равенства):
grammar Foo; program: (statement | exprOtherThanEquality)* ; statement: assignment ; expr: equality | exprOtherThanEquality ; exprOtherThanEquality: boolAndOr ; boolAndOr: atom (BOOL_OP expr)* ; equality: atom EQUAL expr ; assignment: VAR EQUAL expr ENDL ; atom: BOOL | VAR | INT | group ; group: LEFT_PARENTH expr RGHT_PARENTH ; ENDL : ';' ; LEFT_PARENTH : '(' ; RGHT_PARENTH : ')' ; EQUAL : '=' ; BOOL: 'true' | 'false' ; BOOL_OP: 'and' | 'or' ; VAR: [A-Za-z_]+ [A-Za-z_0-9]* ; INT: '-'? [0-9]+ ; WS: [ \t\r\n] -> skip ;Вот дерево синтаксического анализа для входных данных:
В одном из комментариев выше я спросил вас, можем ли мы предположить, что первый знак равенства в строке всегда соответствует заданию. Я немного отклоняю это предположение... Первый знак равенства на линии всегда соответствует присваивание, если оно не заключено в скобки. С приведенной выше грамматикой это допустимая строка:t = (x = 5) and (y = 2);(x = 2). Вот дерево синтаксического анализа: