Протокол буферов в сравнении с JSON и BSON по
есть ли у кого-нибудь информация о характеристиках производительности буферов протокола против BSON (двоичный JSON) или против JSON в целом?
- провод размере
- скорость сериализации
- десериализации скорость
Они кажутся хорошими двоичными протоколами для использования через HTTP. Мне просто интересно, что было бы лучше в долгосрочной перспективе для среды C#.
вот некоторая информация, которую я читал BSON и Протокол Буферы.
4 ответа:
бережливость это еще один протокол буферов, как альтернатива, а также.
есть хорошие тесты от сообщества Java по сериализации / десериализации и размеру провода этих технологий:https://github.com/eishay/jvm-serializers/wiki
В общем, JSON имеет немного больший размер провода и немного хуже DeSer, но выигрывает в повсеместности и способности легко интерпретировать его без исходного IDL. Последний пункт-это то, что Apache Avro пытается решить, и это бьет как с точки зрения производительности.
Microsoft выпустила пакет c# NuGet Microsoft.платформа Hadoop.Авро.
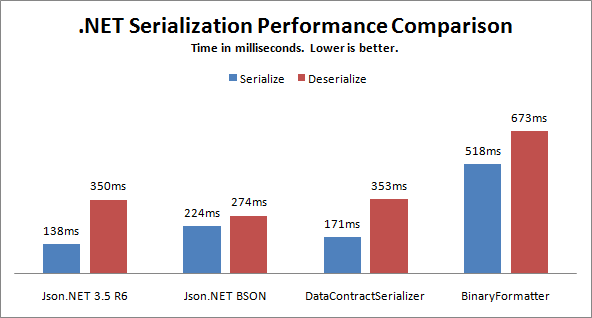
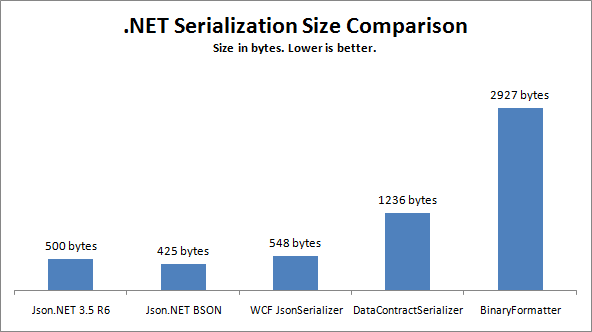
этот пост сравнивает скорости и размеры сериализации в .NET, включая JSON, BSON и XML.
http://james.newtonking.com/archive/2010/01/01/net-serialization-performance-comparison.aspx
здесь некоторые недавние показатели отображение производительности популярных сериализаторов .NET.
The сжигание монахи показатели показать производительность сериализации простой POCO в то время как всеобъемлющий Northwind benchmarks показать объединенные результаты сериализации строки в каждой таблице набора данных Microsoft Northwind.
в основном буферы протокола (protobuf-net) составляет 7x быстрее, чем самый быстрый сериализатор библиотеки базовых классов в .NET (XML DataContractSerializer). Его также меньше, чем конкуренция, как это также 2.2 x меньше, чем Microsofts самый компактный формат сериализации (JsonDataContractSerializer).
текстовые сериализаторы ServiceStack наиболее близки к соответствию производительности двоичной protobuf-сети, где ее Сериализатор Json только 2.58 x медленнее, чем protobuf-чистая.

{kind=link}
{kind=link}
протокол буферов предназначен для провода:
- очень маленький размер сообщения-один аспект является очень эффективным целочисленным представлением переменного размера.
- очень быстрое декодирование - это двоичный протокол.
- protobuf генерирует суперэффективный C++ для кодирования и декодирования сообщений -- подсказка: если вы кодируете все var-целые числа или статические элементы размера в него, он будет кодировать и декодировать с детерминированной скоростью.
- он предлагает очень богатую модель данных -- эффективное Кодирование очень сложных структур данных.
JSON-это просто текст и он должен быть парсится. подсказка: кодирование" миллиарда " int в него займет довольно много символов: Billion = 12 char (длинная шкала), в двоичном формате он вписывается в uint32_t теперь как насчет попытки кодировать двойной? это было бы намного хуже.