Построение квантилей распределения в ggplot2 с гранями
В настоящее время я строю ряд различных распределений первых отличий от ряда регрессионных моделей в ggplot. Чтобы облегчить интерпретацию различий, я хочу отметить 2,5% и 97,5% процентили каждого распределения. Поскольку я буду делать довольно много графиков и поскольку данные сгруппированы в двух измерениях (модель и тип), я хотел бы определить и построить соответствующие процентили в среде ggplot. Построение графиков распределений с использованием фасетов дает мне именно туда, куда я хочу, за исключением процентилей. Я мог бы, конечно, сделать это более вручную, но в идеале я хотел бы найти решение, в котором я все еще могу использовать facet_grid, так как это избавило меня от многих хлопот, пытаясь совместить различные сюжеты вместе.
Вот пример использования смоделированных данных:
df.example <- data.frame(model = rep(c("a", "b"), length.out = 500),
type = rep(c("t1", "t2", "t2", "t1"),
length.outh = 250), value = rnorm(1000))
ggplot(df.example, aes(x = value)) +
facet_grid(type ~ model) +
geom_density(aes(fill = model, colour = model))
ggplot(df.example, aes(x = value)) +
facet_grid(. ~ model) +
geom_density(aes(fill = model, colour = model)) +
geom_vline(aes(x = value), xintercept = quantile(value, probs = c(.025, .975)))
Error in quantile(value, probs = c(0.025, 0.975)) : object 'value' not found
В то время как второй получает мне квантили для полная переменная, а не для субплотностей. То есть построенные квантили идентичны для всех четырех плотностей.
ggplot(df.example, aes(x = value)) +
facet_grid(type ~ model) +
geom_density(aes(fill = model, colour = model)) +
geom_vline(xintercept = quantile(df.example$value, probs = c(.025, .975)))
Очень ценю любой вклад.
3 ответа:
Квантили можно вычислить заранее.
Используя Ваш пример данных:
library (dplyr) d2 <- df.example %>% group_by(model, type) %>% summarize(lower = quantile(value, probs = .025), upper = quantile(value, probs = .975))А затем построить такой сюжет:
ggplot(df.example, aes(x = value)) + facet_grid(type ~ model) + geom_density(aes(fill = model, colour = model)) + geom_vline(data = d2, aes(xintercept = lower)) + geom_vline(data = d2, aes(xintercept = upper))
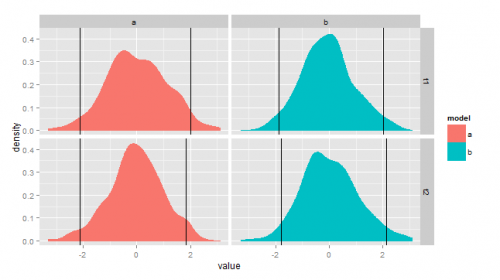
Используйте plyr (или dplyr, data.таблица) для предварительного вычисления этих значений ...
set.seed(1) # ... df.q <- ddply(df.example, .(model, type), summarize, q=quantile(value, c(.025, .975))) p + geom_vline(aes(xintercept=q), data=df.q)
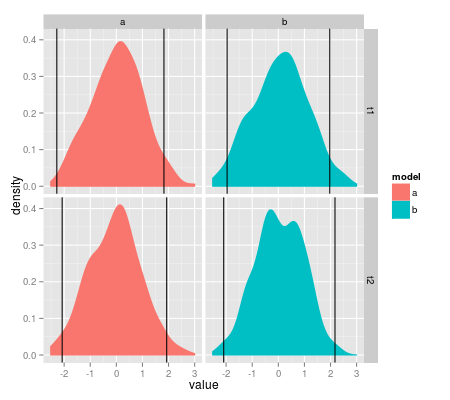
Хороший вопрос. Более общая версия того же вопроса: как вы вызываете функции на подмножествах наборов данных при использовании фасетов? Это кажется очень полезной функцией, и поэтому я искал вокруг, но не мог найти ничего об этом.
Уже приведенные ответы превосходны. Другой вариант-использовать
multiplot()как способ выполнения фасетирования вручную.