Нахождение оптимального правила обучения для ANN
Как найти оптимальное правило обучения для данной задачи, скажем, множественной классификации категорий?
Я думал использовать генетические алгоритмы, но я знаю, что есть проблемы, связанные с производительностью. Я ищу примеры из реального мира, где вы не использовали правила обучения по учебнику, и как вы нашли эти правила обучения.
2 ответа:
Хороший вопрос кстати .
Алгоритмы классификации могут быть классифицированы с использованием многих характеристик , таких как:
Поэтому для вашей задачи классификации нескольких категорий я буду использовать онлайн-логистическую регрессию (из SGD), потому что она идеально подходит для малого и среднего размера данных (меньше, чем десятки миллионов обучающих примеров), и это действительно быстро.
- что сильно предпочитает алгоритм (или какой тип данных наиболее подходит для этого алгоритма).
- накладные расходы на обучение. (требуется ли много времени для обучения)
- когда это эффективно. (большие данные-средние данные-малый объем данных).
- сложность анализов, которые он может доставлять.
Другой Пример:
Предположим, что вам нужно классифицировать большое количество текстовых данных. тогданаивный Байес - Ваш ребенок. потому что он сильно предпочитает текстовый анализ. даже это SVM и SGD быстрее, и, как я испытал, легче тренироваться. но эти правила "SVM и SGD" могут применяться, когда размер данных рассматривается как средний или малый и не большой.В общем случае любой человек, занимающийся интеллектуальным анализом данных, задаст себе четыре упомянутых пункта, когда он хочет начать какой-либо ML или простой проект майнинга.
После этого вы должны измерить его AUC, или любой соответствующий , чтобы посмотреть, что вы сделали. потому что в одном проекте можно использовать не только один классификатор. или иногда, когда вы думаете, что нашли свой идеальный классификатор, результаты, кажется, не очень хороши, используя некоторые методы измерения. поэтому вы снова начнете проверять свои вопросы, чтобы найти, где вы ошиблись.
Надеюсь, что я помог.
Когда вы вводите вектор
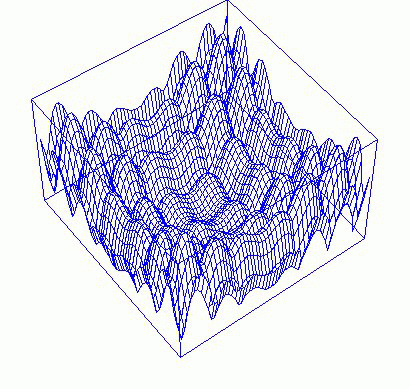
xв сеть, сеть даст выход, зависящий от всех Весов (векторw). Между выводом и истинным ответом будет ошибка. Средняя ошибка (e) является функциейw, скажемe = F(w). Предположим, у вас есть однослойная двухмерная сеть, тогда изображениеFможет выглядеть следующим образом:Когда мы говорим о тренировке, мы на самом деле говорим о нахождении
w, которое делает минимальноеe. В другими словами, мы ищем минимум функции. на поезд в поиск. Итак, вы задаетесь вопросом, Как выбрать метод поиска. Мое предложение было бы следующим: Это зависит от того, как выглядит поверхностьF(w). Чем более волнистым он является, тем более рандомизированный метод следует использовать, потому что простой метод, основанный на градиентном нисхождении, будет иметь больше шансов направить вас в ловушку локального минимума - таким образом, Вы потеряете шанс найти глобальный минимум. С другой стороны сторона, если поверхностьF(w)выглядит как большая яма, то забудьте о генетическом алгоритме. Простое обратное распространение или что-нибудь, основанное на нисхождении градиента, было бы очень хорошо в этом случае. Вы можете спросить, что как я могу знать, как выглядит поверхность? Это навык опыта. Или вы можете случайно выбрать некоторыеwи вычислитьF(w), чтобы получить интуитивное представление о поверхности.