Как создать / указать входные данные AST для тестирования древовидной грамматики с помощью ANTLRWorks?
Фон: я создал грамматику ANTLR. Я могу протестировать и отладить его с помощью ANTLRWorks и проверить, что парсер создает AST, который я имел в виду. Теперь я хочу написать древовидную грамматику для AST, разобрать дерево и отладить древовидную грамматику с помощью ANTLRWorks.
Вопрос: Я хочу протестировать и отладить древовидную грамматику с помощью ANTLRWorks. Таким образом, я хочу разобрать AST, который был создан синтаксическим анализатором. Как указать AST в качестве входных данных при тестировании грамматики дерева с ANTLRWorks?
С. П. Я изучал вопрос / ответ в знает ли кто-нибудь способ отладки древовидных Грамматик в ANTLRWorks, но он не отвечает на мой вопрос. Несмотря на то, что он был принят ОП, он сделал аналогичный комментарий.
1 ответ:
Как указать AST в качестве входных данных при тестировании древовидной грамматики с помощью ANTLRWorks?
Вам не нужно предоставлять AST самостоятельно, только синтаксический анализатор, который производит AST.
Дана следующая грамматика, производящая АСТ:
grammar ASTDemo; options { output=AST; } tokens { ROOT; U_MIN; } parse : expression EOF -> ^(ROOT expression) ; expression : addition ; addition : multiplication (('+' | '-')^ multiplication)* ; multiplication : unary (('*' | '/')^ unary)* ; unary : '-' atom -> ^(U_MIN atom) | atom ; atom : ID | NUMBER | '(' expression ')' -> expression ; ID : ('a'..'z' | 'A'..'Z')+; NUMBER : '0'..'9'+ ('.' '0'..'9'*)?; SPACE : (' ' | '\t' | '\r' | '\n')+ {skip();};Ниже приводится древовидная грамматика для АСТ, полученная с помощью приведенной выше грамматики:
tree grammar ASTDemoWalker; options { output=AST; tokenVocab=ASTDemo; ASTLabelType=CommonTree; } parse : ^(ROOT expression) ; expression : ^('+' expression expression) | ^('-' expression expression) | ^('*' expression expression) | ^('/' expression expression) | ^(U_MIN expression) | atom ; atom : ID | NUMBER ;Обязательно поместите оба файла
ASTDemo.gиASTDemoWalker.gв одну папку. Откройте обе грамматики в ANTLRWorks и сгенерируйте лексер & парсер изASTDemo.gсначала нажатием CTRL+сдвиг+G , а затем сгенерируйте дерево walker, открывASTDemoWalker.gи нажав CTRL+сдвиг+G .Теперь на панели редактора
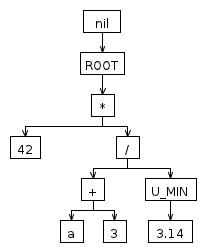
ASTDemoWalker.gзапустите отладчик, нажав CTRL+D и вставьте следующий источник в текстовую область:42 * ((a + 3) / -3.14)И нажмите кнопку OK.
Теперь вы можете пройти через процесс отладки и в конце, вы можете увидеть оба что AST генерирует парсер:
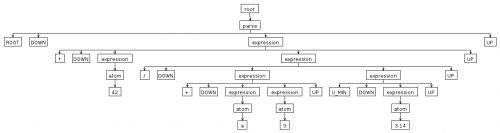
И как ходок по дереву подошел сказал АСТ:
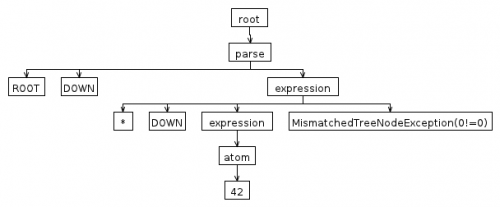
Если вы теперь сделаете "случайную" ошибку в грамматике дерева, скажем, вместо
^('*' expression expression)вы определяете^('*' expression). Если вы снова отладите древовидную грамматику, вы увидите, что она не работает после прохождения узла42:
В AST есть еще один узел после узла
42, в то время как древовидный ходок ожидал только 1 одиночный узел (42) после узла*корневой узел.Конечно, это простая грамматика, но даже если вы знакомы с ANTLR, это иногда боль в@$&, чтобы отслеживать ошибки в грамматике дерева! :)