Как сделать так, чтобы мой процессор i7 достиг 100% использования с этим кодом (самый быстрый способ синтаксического анализа xml)
Как сделать так, чтобы мой процессор i7 достиг 100% использования с этим кодом? Есть ли что-то особенное, что происходит в XmlDocument? это только из-за изменения контекста? и если это так, то почему установка большего количества потоков не заставит процессор использовать свою полную мощность? каков был бы самый верный способ разбора нескольких строк одновременно?
Редактировать:
Возможно, этот код сделает его более понятным, независимо от того, какое количество потоков он использует 30% процессора:
private void Form1_Load(object sender, EventArgs e)
{
Action action = () =>
{
while (true)
{
XmlDocument xmlDocument = new XmlDocument();
xmlDocument.LoadXml("<html><body><div>1111</div><div>222</div></body></html>");
var nodes = xmlDocument.SelectNodes("//div");
}
};
Parallel.For(0, 16, i => action());
}
4 ответа:
В вашем примере кода (и вы увидите это с помощью профилировщика) вы тратите много времени на ожидание доступных ресурсов для запуска этих потоков. Поскольку вы постоянно запрашиваете все больше и больше
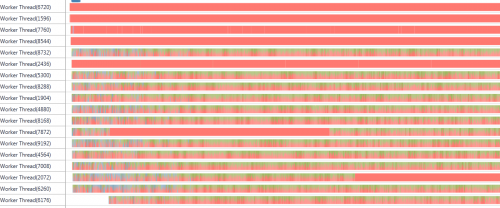
Parallel.For(что является неблокирующим вызовом) - ваш процесс тратит значительное время на ожидание завершения потоков, а затем на выбор следующего потока (постоянно растущее количество таких потоков все время запрашивает время для запуска).Рассмотрим этот вывод из профилировщика:
Красный цвет это синхронизация! Посмотрите, сколько работы выполняется ядром, чтобы позволить моему приложению запускать так много потоков! Заметьте, если бы у вас был одноядерный процессор, вы бы определенно увидели 100%
Вы получите лучшее время для чтения этого xml, разделив строку и проанализировав их отдельно (после загрузки из ввода-вывода, конечно). Вы можете не увидеть 100% загрузки процессора, но это будет лучшим вариантом. Играйте с различными размерами разделов строки (т. е. размерами подстрок).
Для удивительно читать о параллельных паттернах, я рекомендую эту статью Стивена Тоуба: http://download.microsoft.com/download/3/4/D/34D13993-2132-4E04-AE48-53D3150057BD/Patterns_of_Parallel_Programming_CSharp.pdf
EDIT я искал умный способ чтения xml в нескольких потоках. Мой лучший совет таков:
- разбейте xml-файлы на файлы меньшего размера, если это возможно.
- используйте один поток для каждого xml-файла.
- Если 1 и 2 недостаточно для вас perf необходимо, рассмотреть возможность не загрузки его как xml полностью, а разбиения строки (разбиение ее) и разбора немного вручную (не в XmlDocument). Я бы сделал это только в том случае, если 1 и 2 достаточно хороши для ваших нужд. Каждая секция (подстрока) будет работать в своем собственном потоке. Помните также, что "больше тредов"!= "больше использования процессора", по крайней мере, не для вашего приложения. Как мы видим в Примере профилировщика, слишком много потоков стоит больших накладных расходов. Все должно быть просто.
Это фактический код, который вы запускаете, или вы загружаете xml из файла или другого URL-адреса? Если это фактический код, то он, вероятно, завершается слишком быстро, и CLR не успевает оптимизировать количество потоков, но когда вы ставите бесконечный цикл, это гарантирует, что вы максимизируете процессоры.
Если вы загружаете XML из реальных источников, то потоки могут ожидать ответов ввода-вывода, и это не будет потреблять процессор, пока это происходит. Чтобы ускорить это дело, вы можете предварительно загрузить все XML, используя много потоков (например, 20+) в память, а затем использовать 8 потоков, чтобы сделать синтаксический анализ XML после этого.
Процессор-самый быстрый компонент на современном ПК. Узкие места часто бывают в виде оперативной памяти или жестких дисков. В первом случае вы постоянно создаете переменную, которая потенциально может поглотить много памяти. Таким образом, интуитивно понятно, что ОЗУ становится узким местом, поскольку кэш быстро иссякает.
Во втором случае вы не создаете никаких переменных (я уверен, что .NET делает много в фоновом режиме, хотя и очень оптимизированным способом). Итак, его интуитивный, что вся работа остается на центральном процессоре.
Невозможно полностью определить, как ОС обрабатывает память, прерывания и т. д. Вы можете использовать инструменты, которые помогают определить эти ситуации, но в прошлый раз я проверил, что нет даже анализатора памяти для кода .NET. Вот почему я говорю, что нужно отнестись к ответу серьезно.
Параллельная библиотека задач распределяет действия, поэтому вы теряете немного контроля, когда дело доходит до использования процесса. По большей части это хорошо, потому что нам не нужно беспокоиться о создании слишком большого количества потоков, делать наши потоки слишком большими и т. д. Если вы хотите явно создавать потоки, то следующий код должен толкать ваш процессор на максимум:
Parallel.For(0, 16, index => new Thread(() => { while (true) new Thread(() => { XmlDocument xmlDocument = new XmlDocument(); xmlDocument.LoadXml("<html><body><div>1111</div><div>222</div></body></html>"); var nodes = xmlDocument.SelectNodes("//div"); }).Start(); }).Start());Я не говорю, что рекомендую этот подход, просто показываю рабочий пример кода, толкающего мой процессор на максимум (AMD FX-6200). Я видел, что около 30% используют параллельную библиотеку задач.