Как применять операции над строками фрейма данных, но с переменными столбцами, затронутыми?
У меня есть фрейм данных, который считывается из csv и содержит посторонние данные. Суждение о том, что является посторонним, делается путем оценки одной колонки, SystemStart. Любые данные в строке, которая находится в столбце с заголовком значения даты ниже, чем SystemStart для этой строки, устанавливается значение nan. Например, index = ' one 'имеет дату начала системы '2016-1-5', и когда pd.date_range настроен, он не имеет значений nan для заполнения. index= 'three' - это '2016-1-7' и, следовательно, имеет два значения nan, заменяющих исходное значение данные.
Я могу идти ряд за рядом и бросать np.nan значения во всех столбцах, но это медленно. Есть ли более быстрый способ?
Ниже я создал репрезентативный фрейм данных и хочу получить тот же результат без итерационных операций или способа ускорить эти операции. Любая помощь будет очень признательна.
import pandas as pd
import numpy as np
start_date = '2016-1-05'
end_date = '2016-1-7'
dates = pd.date_range(start_date, end_date, freq='D')
dt_dates = pd.to_datetime(dates, unit='D')
ind = ['one', 'two', 'three']
df = pd.DataFrame(np.random.randint(0,100,size=(3, 3)), columns = dt_dates, index = ind)
df['SystemStart'] = pd.to_datetime(['2016-1-5', '2016-1-6', '2016-1-7'])
print 'Initial Dataframe: n', df
for msn in df.index:
zero_date_range = pd.date_range(start_date, df.loc[msn,'SystemStart'] - pd.Timedelta(days=1), freq='D')
# we set zeroes for all columns in the index element in question - this is a horribly slow way to do this
df.loc[msn, zero_date_range] = np.NaN
print 'nAltered Dataframe: n', df
Ниже приведены выходные данные df, начальные и измененные:
Initial Dataframe:
2016-01-05 00:00:00 2016-01-06 00:00:00 2016-01-07 00:00:00
one 24 23 65
two 21 91 59
three 62 77 2
SystemStart
one 2016-01-05
two 2016-01-06
three 2016-01-07
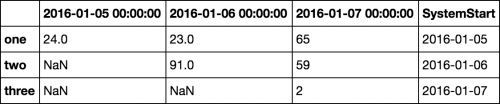
Altered Dataframe:
2016-01-05 00:00:00 2016-01-06 00:00:00 2016-01-07 00:00:00
one 24.0 23.0 65
two NaN 91.0 59
three NaN NaN 2
SystemStart
one 2016-01-05
two 2016-01-06
three 2016-01-07
1 ответ:
Первое, что я делаю, это удостоверяюсь, что
SystemStartявляетсяdatetimedf.SystemStart = pd.to_datetime(df.SystemStart)Затем я выделяю
SystemStartв отдельную сериюst = df.SystemStartЗатем я отбрасываю
SytstemStartиз моегоdfd1 = df.drop('SystemStart', 1)Затем я преобразую оставшиеся столбцы в
datetimed1.columns = pd.to_datetime(d1.columns)Наконец, я использую
numpyшироковещание, чтобы замаскировать соответствующие ячейки и присоединитьSystemStartобратно.d1.where(d1.columns.values >= st.values[:, None]).join(st)