Добавление недостающего уровня фактора в тепловую карту ggplot2
У меня есть тепловая карта на основе ggplot2, которая отображает количество вхождений определенных факторов. Однако в разных наборах данных иногда отсутствуют экземпляры некоторых факторов, что означает, что их соответствующие тепловые карты будут выглядеть по-разному. Чтобы упростить параллельное сравнение, я хотел бы добавить недостающие уровни. К сожалению, мне это не удалось.
Итак, у меня есть данные, которые выглядят следующим образом:
> head(numRules)
Job Generation NumRules
1 0 0 2
2 0 1 1
3 0 2 1
4 0 3 1
5 0 4 1
6 0 5 1
> levels(factor(numRules$NumRules))
[1] "1" "2" "3"
Я использую следующий код для отображения хорошей тепловой карты, которая подсчитывает количество правила на поколение для всех рабочих мест:
ggplot(subset(numRules, Generation < 21), aes(x=Generation, y=factor(NumRules))) +
stat_bin(aes(fill=..count..), geom="tile", binwidth=1, position="identity") +
ylab('Number of Rules')
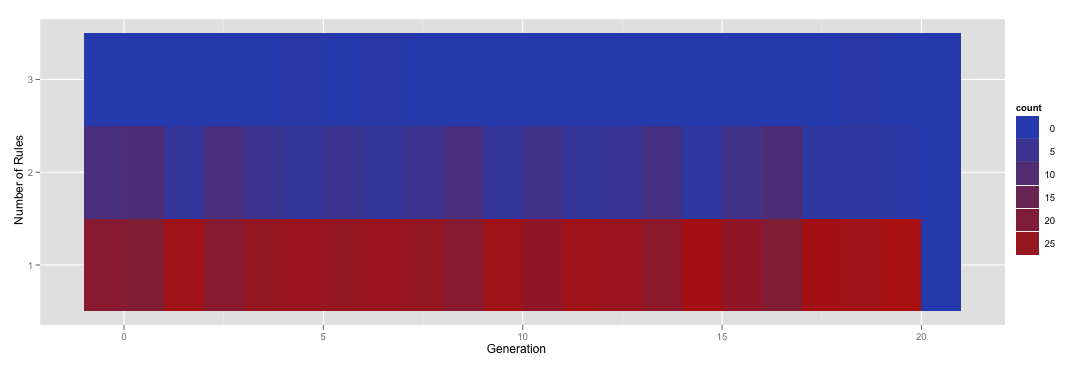
Тепловая карта подсчета количества правил по генерации для всех заданий
Итак, тепловая карта говорит,что в большинстве случаев прогоны имеют только одно правило для данного поколения, но иногда вы получаете два, а в редких случаях вы получите три. Теперь совершенно другой набор запусков может фактически иметь нулевые правила для данного поколения. Тем не менее, проведение параллельного сравнения было бы немного запутанным, потому что y ось одной тепловой карты имеет число правил в [1,3], а другая может быть в [0,2]. Что я хотел бы сделать, так это стандартизировать тепловые карты так, чтобы они все имели уровни коэффициентов в (0,1,2,3) независимо от количества правил. Например, я хотел бы повторно отобразить приведенную выше тепловую карту, чтобы включить строку для нулевых правил, даже если в этом конкретном фрейме данных нет примеров этого.Я потрепал это различными заклинаниями R, включающими в себя установку разрывов и весов и тому подобное но безрезультатно. Интуиция подсказывает мне, что есть простое решение этой проблемы, но я не могу его найти.
Обновление :
Если я вручную укажу уровни в вызове factor, я получу строку, добавленную для нулевых правил:
ggplot(subset(numRules, Generation < 21), aes(x=Generation, y=factor(NumRules,levels=c("0","1","2","3")))) + stat_bin(aes(fill=..count..), geom="tile", binwidth=1, position="identity") + ylab('Number of Rules')
Который дает этот.
К сожалению, как вы можете видеть, эта новая строка не имеет правильного цвета. Добраться туда!2 ответа:
В этой ситуации было бы проще изменить ваши данные. Во-первых, прочитайте ваши данные. Затем установите переменную
NumRulesна множитель со всеми необходимыми уровнями (от 0 до 3)Теперь вычислите, сколько раз каждая комбинацияnumRules = read.table(text=" Job Generation NumRules 1 0 0 2 2 0 1 1 3 0 2 1 4 0 3 1 5 0 4 1 6 0 5 1", header=TRUE) numRules$NumRules = factor(numRules$NumRules, levels=c(0, 1, 2, 3))NumRulesиGenerationприсутствует в ваших данных с функциейtable()и сохраните ее в некоторый объект.tab<-table(numRules$NumRules,numRules$Generation) tab 0 1 2 3 4 5 0 0 0 0 0 0 0 1 0 1 1 1 1 1 2 1 0 0 0 0 0 3 0 0 0 0 0 0С помощью функции
melt()из библиотекиreshape2сделайте эту таблицу в длинном формате и измените имена столбцовlibrary(reshape2) tab.long<-melt(tab) colnames(tab.long)<-c("NumRules","Generation","Count")Постройте график данных с использованием нового фрейма данных.
geom_tile()и установкаfill=в столбец, содержащий фактические подсчеты.ggplot(tab.long, aes(x=Generation, y=NumRules,fill=Count)) + geom_tile() + ylab('Number of Rules')

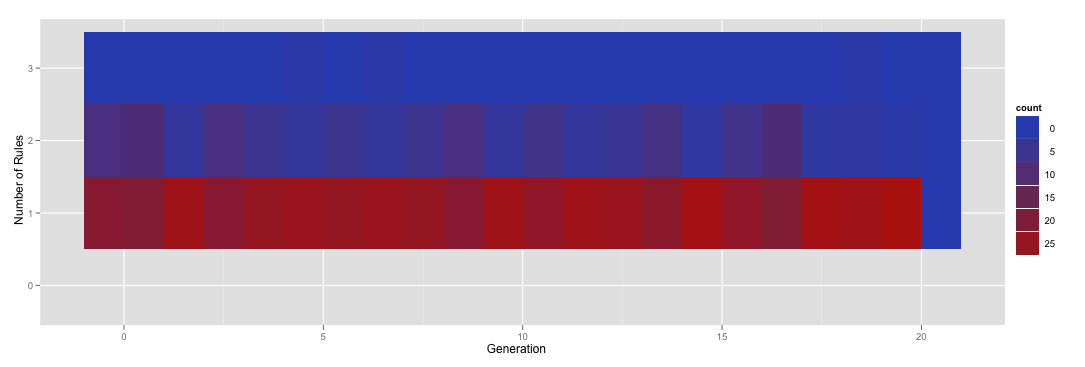
Если все
NumRules, которые вас интересуют, являются уровнями фактора, то вы можете исправить это, просто указавdrop=FALSEвscale_y_discrete():numRules = read.table(text=" Job Generation NumRules 1 0 0 2 2 0 1 1 3 0 2 1 4 0 3 1 5 0 4 1 6 0 5 1", header=TRUE) numRules$NumRules = factor(numRules$NumRules, levels=c(1, 2, 3)) ggplot(subset(numRules, Generation < 21), aes(x=Generation, y=NumRules)) + scale_y_discrete(drop=FALSE) + stat_bin(aes(fill=..count..), geom="tile", binwidth=1, position="identity") + ylab('Number of Rules')Результат:

{kind=link}
{kind=link}