что такое тусклость, что такое факт?
У меня есть приложение, которое, как я знаю, сделает отличный куб и будет полезно для большего, чем стандартный плоский отчет служб Reporting Services. Мы собираемся перейти к Би-вещам с консультантом, но я хотел бы дать ему шанс, прежде чем мы это сделаем, главным образом, чтобы я знал, что мы собираемся делать.
Приложение отслеживает опросы в домах престарелых по всей стране. Они могут быть ежегодными, жалобами или несколькими другими типами опросов, у них есть штрафы, связанные с указанными тегами, и иметь документацию, связанную с ними. Что я хотел бы сделать, так это придумать способ, который позволит нам использовать имеющиеся у нас данные - сколько тегов во Флориде за июнь? Сколько объектов вовремя доставили свою документацию? Сколько ежегодных (неожиданных) опросов произошло в 1-м квартале этого года по сравнению с прошлым годом?Я включаю схемы в надежде, что кто-то сможет сказать мне не только то, что является тусклым и что является фактом, но и какие данные идут где. Думаю, это будет отличное начало.
Все, что угодно, было бы действительно полезно. Я пытаюсь настроить небольшую витрину данных, в то время как я вливаю в хранилище данных Lifecycle Toolkit от Kimball.Спасибо! M@
Таблица сущностей-это список всех наших объектов: первичный ключ-это пятибуквенный код, обозначающий зданиеCREATE TABLE [dbo].[Entity](
[entID] [varchar](10) NOT NULL,
[entShortName] [varchar](150) NULL,
[entNumericID] [int] NOT NULL,
[orgID] [int] NOT NULL,
[regionID] [int] NOT NULL,
[portID] [int] NOT NULL,
[busTypeID] [int] NOT NULL,
[adpID] [varchar](50) NULL,
[eHealthDataID] [varchar](50) NULL,
[updateDate] [datetime] NULL CONSTRAINT [DF_Entity_updateDate] DEFAULT (getdate()),
[powProID] [int] NULL,
[regionReportingID] [int] NULL,
[regionPresEmail] [varchar](300) NULL,
[regionClinDirEmail] [varchar](300) NULL,
CONSTRAINT [PK_EntityNEW] PRIMARY KEY CLUSTERED
(
[entID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 75) ON [PRIMARY]
) ON [PRIMARY]
Обзор Главный
CREATE TABLE [dbo].[surveyMain](
[surveyID] [int] IDENTITY(1,1) NOT NULL,
[surveyDateFac] AS (([facility]+'-')+CONVERT([varchar],[surveyDate],(101))),
[surveyDate] [datetime] NOT NULL,
[surveyType] [int] NOT NULL,
[surveyBy] [int] NULL,
[facility] [varchar](10) NOT NULL,
[originalSurvey] [int] NULL,
[exitDate] [datetime] NULL,
[dpnaDate] AS (dateadd(month,(3),[exitDate])),
[clearedTags] [varchar](1) NULL,
[substantiated] [varchar](1) NULL,
[firstRevisit] [int] NULL,
[secondRevisit] [int] NULL,
[thirdRevisit] [int] NULL,
[fourthRevisit] [int] NULL,
[updated] [datetime] NULL CONSTRAINT [DF_surveyMain_updated] DEFAULT (getdate()),
CONSTRAINT [PK_tagSurvey] PRIMARY KEY CLUSTERED
(
[surveyID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 90) ON [PRIMARY]
) ON [PRIMARY]
Типы Опросов:
CREATE TABLE [dbo].[surveyTypes](
[surveyTypeID] [int] IDENTITY(1,1) NOT NULL,
[surveyTypeDesc] [varchar](100) NOT NULL,
CONSTRAINT [PK_surveyTypes] PRIMARY KEY CLUSTERED
(
[surveyTypeID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
Файлы Опросов
CREATE TABLE [dbo].[surveyFiles](
[surveyFileID] [int] IDENTITY(1,1) NOT NULL,
[surveyID] [int] NOT NULL,
[surveyFilesTypeID] [int] NOT NULL,
[documentDate] [datetime] NOT NULL,
[responseDate] [datetime] NULL,
[receiptDate] [datetime] NULL,
[dateCertain] [datetime] NULL,
[fileName] [varchar](250) NULL,
[fileUpload] [image] NULL,
[fileDesc] [varchar](100) NULL,
[updated] [datetime] NOT NULL CONSTRAINT [DF_surveyFiles_updated] DEFAULT (getdate()),
CONSTRAINT [PK_surveyFiles] PRIMARY KEY CLUSTERED
(
[surveyFileID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 75) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
Обзор Штрафы
CREATE TABLE [dbo].[surveyFines](
[surveyFinesID] [int] IDENTITY(1,1) NOT NULL,
[surveyID] [int] NULL,
[surveyFinesTypeID] [int] NULL,
[dateRecommended] [datetime] NULL,
[dateImposed] [datetime] NULL,
[totalFineAmt] [varchar](100) NULL,
[wasImposed] [varchar](3) NULL,
[dateCleared] [datetime] NULL,
[comments] [varchar](500) NULL,
[updated] [datetime] NOT NULL CONSTRAINT [DF_surveyFines_updated] DEFAULT (getdate()),
CONSTRAINT [PK_surveyFines] PRIMARY KEY CLUSTERED
(
[surveyFinesID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 75) ON [PRIMARY]
) ON [PRIMARY]
Теги Опроса
CREATE TABLE [dbo].[surveyTags](
[seq] [int] IDENTITY(1,1) NOT NULL,
[surveyID] [int] NOT NULL,
[tagDescID] [int] NOT NULL,
[tagStatus] [int] NULL,
[scopesev] [varchar](5) NOT NULL,
[comments] [varchar](1000) NULL,
[clearedDate] [datetime] NULL,
[updated] [datetime] NULL CONSTRAINT [DF_surveyTags_updated] DEFAULT (getdate()),
CONSTRAINT [PK_tagMain] PRIMARY KEY CLUSTERED
(
[seq] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 90) ON [PRIMARY]
) ON [PRIMARY]
4 ответа:
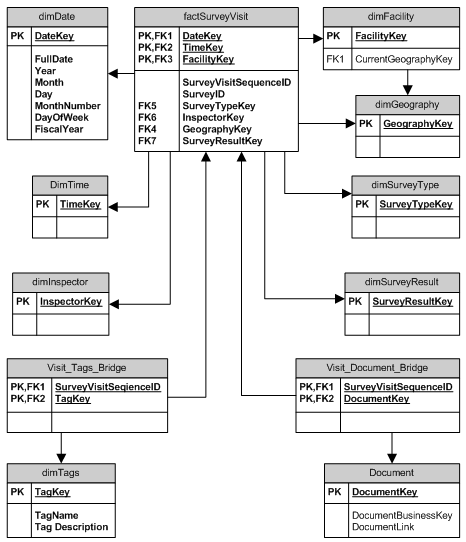
Это довольно сложная задача для форума поддержки, поэтому я остановлюсь только на одной части проблемы. Кажется, что один опрос может состоять из нескольких посещений, поэтому я бы предложил factSurveyVisit с зерном одного посещения-события. СтолбецSurveyID действует как вырожденное измерение в этой модели и является общим для всех посещений из одного и того же обзора. SurveyVisitSequenceID является уникальным автоинкрементом (целым числом) и используется для упрощения связывания двух мостовых таблиц для документов и метки к таблице фактов.
Вы также можете продвинуть опрос в полное измерение dimSurvey , чтобы добавить некоторые заметки и т. д.; Используйте SurveyID для ссылки.
Я не рассматривал здесь штрафы, для этого я бы предложил factFine таблицу, которая будет иметь свои собственные ссылки на dimDate, тусклое время, dimFacility и т. д. Таким образом, отчеты о штрафах ($$) могут быть сделаны быстро, не присоединяясь к большинству таблиц, связанных с посещением. Там же должен быть мост. таблица присоединения factFine к factSurveyVisit, предусматривающая штрафы, связанные с каждым посещением, а не с завершенным обследованием.
EDIT
Только что заметил, что ваша таблицаTag имеет date_cleared, так что, по общему признанию, я не понимаю тегов в этом бизнесе. В модели dimTag - это просто список доступных тегов. Может быть еще один factFacilityStatus таблица, связывающая dimFacility и dimTag , отслеживающий статус тега для каждого объекта.
Что я хотел бы сделать, так это придумать способ, который позволит нам использовать имеющиеся у нас данные - сколько тегов во Флориде за июнь? Сколько объектов вовремя доставили свою документацию? Сколько ежегодных (неожиданных) опросов произошло в 1 квартале этого года по сравнению с прошлым годом?Размерность - это диапазон измерений. Диапазон измерений может быть непрерывным, как даты, или дискретным, как объекты. В ваших вопросах: измерения-это объект и дата, дата/время и дата соответственно.
Только так можно ответить на вопрос "сколько меток во Флориде за июнь месяц?- это связывать метки с объектами и метки с датами.
Только так можно ответить на вопрос "сколько объектов вовремя сдавали свою документацию?"заключается в том, чтобы связать поставку документации с объектом и дату сдачи с объектом.
Вы должны следовать тому же самому аналитическому процессу с остальные вопросы или запросы, на которые вы ожидаете ответа от хранилища данных.
Факт - это сущность или объект. Бирка-это факт. Доставка документации-это факт. Факты почти всегда остаются неизменными в хранилище данных после их загрузки.
Что касается вашей схемы, я бы изучил ее подробнее, чтобы дать конкретные рекомендации, но в целом вы хотите использовать звездная схема. Центр звезды(звезд) - это ваши факты, сущности и объекты. Стол которые составляют точки звезды - это ваши таблицы измерений.
Первое, что вам нужно сделать, это отделить ваши факты от ваших измерений. Ни одна из ваших таблиц сущностей не должна содержать дат, кодов местоположения или чего-либо еще, что вы определяете как измерение. Однако таблицы фактов будут содержать внешние ключи для таблиц дат, таблиц местоположений или других таблиц измерений.Вам, вероятно, также понадобятся сводные таблицы. Сводные таблицы содержат те же столбцы, что и таблицы фактов. сложение одной или нескольких сумм в разных измерениях. В качестве примера можно привести вопрос "сколько меток во Флориде за июнь месяц?"можно ответить гораздо быстрее, если у вас уже есть сумма тегов для Флориды (или, точнее, каждого объекта во Флориде) за месяц (или каждый из дней) июня 2010 года.
Период, который вы суммируете, зависит от смеси запросов, которые вы ожидаете. В вашем хранилище данных день может быть слишком коротким периодом. Другими словами, это так же быстро чтобы сделать резюме в SQL, как это делается, чтобы выбрать строку резюме.
Вам понадобится таблица календаря - тоже. Календарная таблица задает вопросы типа :" сколько ежегодных (неожиданных) опросов произошло в 1-м квартале этого года по сравнению с (1-м кварталом) прошлого года?- гораздо проще задавать вопросы.
Похоже, что у вас есть несколько штрафов, файлов и тегов для каждого опроса.
Я ожидал бы 4 таблицы фактов - с фактами в каждой, выглядящими так, как будто они в основном являются данными datetime (хотя они часто моделируются как роли измерения даты и / или времени - я сделал здесь пару заметок, но флаги обычно будут в измерениях):
SurveyMain
SurveyFine (wasImposed находится в измерении, связанном с этим фактом, totalFineAmt является фактом в этом Таблица)
SurveyFile
SurveyTag
Все они будут иметь общее измерение обзора, и я пойду вперед и разделю измерение объекта/объекта в каждом из них. Вы могли бы снежинка через измерение съемки, но это побеждает наиболее выгодную точку звездных моделей, позволяющих получить все данные непосредственно вместо того, чтобы идти через мостовые таблицы.
У вас есть возможность поместить тип опроса в его собственное измерение (или, возможно, в мусорное измерение) или получить к нему доступ через измерение обзора (не через снежинку). Это типично для размерного моделирования - вам не нужно следовать за вашими сущностями - вам просто нужно избегать ловушки слишком большого количества измерений и слишком малого количества измерений и следить за кардинальностью ваших измерений-особенно если вы случайно включили какое-то вырожденное измерение, например номер счета, который меняется с каждым фактом и поэтому должен храниться в таблице фактов.
На самом деле, иногда проще сделать ваши звездные модели с помощью выполнение типичных соединений в вашем 3NF, которые создают типичные плоские представления отчетов, а затем просто берут эти плоские строки и превращают их в звезды. (Вот как мало релевантности модель сущностных отношений действительно имеет к размерной модели). Таким образом, Вы можете присоединить SurveyMain к SurveyTypes и SurveyFine на ваших текущих нормализованных ключах и посмотреть на все столбцы. Это будет основой для таблицы фактов SurveyFine. То же самое и с другими таблицами фактов, которые я идентифицировал. Общий материал был бы a кандидат для общих измерений. Объект является хорошим кандидатом для согласованного измерения (то есть он будет разделен между этими моделями опроса и другими моделями, связанными с вашей компанией, например, HR - моделями или моделями бухгалтерского учета).
Я бы настроил таблицы фактов SurveyFines, SurveyTag и SurveyFiles, все они являются различными зернами фактов, и все они представляют собой наименьшее зерно.
Все они будут иметь с собой измерения даты, сущности и обзора.
Затем я бы настроил предварительно агрегированные таблицы метрик для тех метрик, которые могли бы объединить все три факта.
Если вы хотите, чтобы я уточнил, не стесняйтесь спрашивать. Я сегодня немного тороплюсь.
(продолжение...) Мне кажется, что ваши пользователи хотят свернуть измеримые данные (количество файлов, дата отправки файлов, сумма штрафов). Они хотят посмотреть на эти показатели по атрибутам опроса. Вот почему я предлагаю измерение обзора.
Учитывая ваш комментарий ниже, я мог бы затем построить таблицу предагрегатных метрик,
Дата (Дата загрузки таблицы метрик) SurveyDimID EntityDimID NumTagsAssigned NumFilesRequested NumFilesReceived NumFines TotalFines и т.д...
Я бы загружал эту таблицу каждый день с полным набором активных данных опроса из моих таблиц фактов. Это позволяет пользователям переходить назад и вперед по истории, чтобы увидеть, как пришел опрос.
Я полагаю, что в какой-то момент весь процесс обследования завершен, и в этот момент эти записи не будут включены в метрическую нагрузку. (Они останутся в фактах).