Чтение Запись Структурированного Двоичного Файла
Я хочу прочитать записать двоичный файл, который имеет следующую структуру:
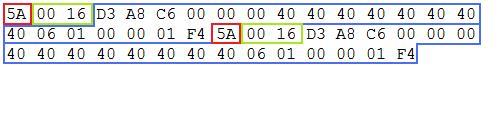
Файл состоит из "записей". Каждая "запись" имеет следующую структуру: Я буду использовать первую запись в качестве примера
- (красный)начальный байт: 0x5A (всегда 1 байт, фиксированное значение 0x5A)
- (зеленый) длина байт: 0x00 0x16 (всегда 2 байта, значение может изменяться от "0x00 0x02" to "0xFF 0xFF")
- (синий) содержание: количество байт, обозначенное десятичным значением поля LENGTH минус 2. В этом случае значение поля length равно 22 (0x00 0x16, преобразованное в десятичное число), поэтому содержимое будет содержать 20 (22 - 2) байт.
private void Read(BinaryReader binaryReader, BinaryWriter binaryWriter)
{
byte START = 0x5A;
int decimalLenght = 0;
byte[] content = null;
byte[] length = new byte[2];
while (binaryReader.PeekChar() != -1)
{
//Check the first byte which should be equals to 0x5A
if (binaryReader.ReadByte() != START)
{
throw new Exception("0x5A Expected");
}
//Extract the length field value
length = binaryReader.ReadBytes(2);
//Convert the length field to decimal
int decimalLenght = GetLength(length);
//Extract the content field value
content = binaryReader.ReadBytes(decimalLenght - 2);
//DO WORK
//modifying the content
//Writing the record
Write(binaryWriter, content, length, START);
}
}
private void Write(BinaryWriter binaryWriter, byte[] content, byte[] length, byte START)
{
binaryWriter.Write(START);
binaryWriter.Write(length);
binaryWriter.Write(content);
}
Этот способ действительно работает. Однако, поскольку я имею дело с очень большими файлами, я считаю, что он вообще не работает, потому что я читаю и пишу 3 раза для каждой записи. На Самом Деле Я хотел бы читать баги кусками данных вместо небольшого количества байтов и, возможно, работать в памяти, но мой опыт использования потока останавливается с BinaryReader и BinaryWriter. Заранее спасибо.
2 ответа:
FileStreamон уже буферизован, поэтому я бы ожидал, что он будет работать довольно хорошо. Вы всегда можете создатьBufferedStreamвокруг исходного потока, чтобы добавить дополнительную буферизацию, если вам действительно нужно, но я сомневаюсь, что это будет иметь существенное значение.Вы говорите, что это "не работает вообще" - как быстро это работает? Насколько вы уверены, что Ио-это то, куда уходит ваше время? Выполняли ли вы какое-либо профилирование кода?
Я также могу предложить вам прочитать 3 (или 6?) байт изначально, а не 2 отдельных чтения. Поместите начальные байты в небольшой массив, проверьте 5A ck-байт, затем индикатор длины 2 байта, затем 3 байта AFP op-код, затем прочитайте оставшуюся часть записи AFP.
Это небольшая разница, но она избавляет от одного из ваших вызовов чтения.
Я не Джон Скит, но я работал в одном из крупнейших печатных и почтовых магазинов в стране довольно долгое время, и мы делали в основном продукцию AFP :- )
(обычно в C, хотя)