bash, Linux: установить разницу между двумя текстовыми файлами
у меня есть два файла A -nodes_to_delete и B -nodes_to_keep. Каждый файл имеет много строк с числовыми идентификаторами.
Я хочу иметь список числовых идентификаторов в nodes_to_delete а не nodes_to_keep, например, alt текст http://mathworld.wolfram.com/images/equations/SetDifference/Inline1.gif.
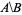{kind=link}
в базе данных PostgreSQL неоправданно медленно. Любой аккуратный способ сделать это в bash с помощью инструментов Linux CLI?
обновление: этот казалось бы, типичный для Python работа, но файлы очень большие. Я решил некоторые подобные проблемы с помощью uniq,sort и некоторые методы теории множеств. Это было примерно на два или три порядка быстрее, чем эквиваленты базы данных.
5 ответов:
The comm это.
кто-то показал мне, как именно это сделать в sh пару месяцев назад, а затем я не мог найти его некоторое время... и пока я смотрел, я наткнулся на ваш вопрос. Вот это :
set_union () { sort | uniq } set_difference () { sort | uniq -u } set_symmetric_difference() { sort | uniq -u }
использовать
comm- он будет сравнивать два отсортированных файла строка за строкойответ на вопрос OP, используя этот пример настройки, появляется ниже. Эта команда вернет строки, уникальные для deleteNodes, а не в keepNodes
comm -1 -3 <(sort keepNodes) <(sort deleteNodes)пояснение: показать строки, уникальные для deleteNodes, скрыть другие строки
пример настройки
мы будем использовать keepNodes и deleteNodes. Они используются как несортированные вход.
$ cat > keepNodes <(echo bob; echo amber;) $ cat > deleteNodes <(echo bob; echo ann;)по умолчанию без аргументов comm печатает 3 столбца
unique_to_FILE1 unique_to_FILE2 lines_appear_in_bothэто пример barebones
commбез аргументов. Обратите внимание на три колонки.$ comm <(sort keepNodes) <(sort deleteNodes) amber ann bobподавление вывода столбца
подавить столбец 1, 2 или 3 с помощью-N; обратите внимание, что когда столбец скрыт, пробелы сжимаются.
$ comm -1 <(sort keepNodes) <(sort deleteNodes) ann bob $ comm -2 <(sort keepNodes) <(sort deleteNodes) amber bob $ comm -3 <(sort keepNodes) <(sort deleteNodes) amber ann $ comm -1 -3 <(sort keepNodes) <(sort deleteNodes) ann $ comm -2 -3 <(sort keepNodes) <(sort deleteNodes) amber $ comm -1 -2 <(sort keepNodes) <(sort deleteNodes) bobон не будет изящно, когда вы забудете сортировать
comm: file 1 is not in sorted order
commбыл специально разработан для такого случая использования, но он требует отсортированного ввода.
awkвозможно, это лучший инструмент для этого, поскольку он довольно прямо вперед, чтобы найти разницу в наборе, не требуетsort, и предлагает дополнительную гибкость.awk 'NR == FNR { a[]; next } !( in a)' nodes_to_keep nodes_to_deleteвозможно, например, вы хотели бы найти только разницу в строках, которые представляют неотрицательные числа:
awk -v r='^[0-9]+$' 'NR == FNR && ~ r { a[] next } ~ r && !( in a)' nodes_to_keep nodes_to_delete
может быть, вам нужен лучший способ сделать это в postgres, я могу поспорить, что вы не найдете более быстрый способ сделать это с помощью плоских файлов. Вы должны быть в состоянии сделать простое внутреннее соединение и предполагая, что оба идентификатора cols индексируются, что должно быть очень быстро.