Apache Spark DAG поведение когруппированная операция
Я хотел бы получить некоторые разъяснения о поведении DAG, и как именно была выполнена следующая работа:
val rdd = sc.parallelize(List(1 to 10).flatMap(x=>x).zipWithIndex,3)
.partitionBy(new HashPartitioner(4))
val rdd1 = sc.parallelize(List(1 to 10).flatMap(x=>x).zipWithIndex,2)
.partitionBy(new HashPartitioner(3))
val rdd2 = rdd.join(rdd1)
rdd2.collect()
Это связано rdd2.toDebugString:
(4) MapPartitionsRDD[6] at join at IntegrationStatusJob.scala:92 []
| MapPartitionsRDD[5] at join at IntegrationStatusJob.scala:92 []
| CoGroupedRDD[4] at join at IntegrationStatusJob.scala:92 []
| ShuffledRDD[1] at partitionBy at IntegrationStatusJob.scala:90 []
+-(3) ParallelCollectionRDD[0] at parallelize at IntegrationStatusJob.scala:90 []
+-(3) ShuffledRDD[3] at partitionBy at IntegrationStatusJob.scala:91 []
+-(2) ParallelCollectionRDD[2] at parallelize at IntegrationStatusJob.scala:91 []
Это образ пользовательского интерфейса spark:
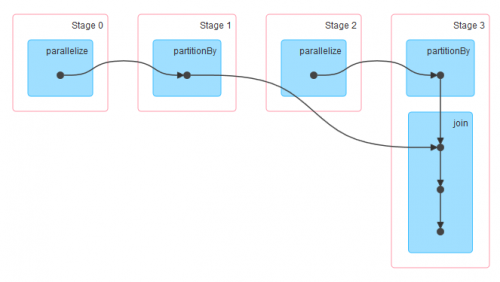
Глядя на toDebugString и на пользовательский интерфейс spark, если я хорошо понял, чтобы выполнить соединение, DAG смотрит на то, какой разделитель следует использовать, и поскольку оба RDD являются HashPartitioned, он выбирает разделитель с большим числом разделов, поэтому rdd разделитель.
Теперь из пользовательского интерфейса spark, кажется, что rdd partitionBy и join выполняется в той же стадии, так что при этих условиях перетасовка, необходимая для выполнения соединения, будет выполнена только с одной стороны? С одной стороны, я имею в виду, что только rdd1 будет перетасован и нет обоих.
Верно ли мое предположение?